·大公司拥有资源、算力和场景优势,却难以维持“天才英雄”的技术自主权;而创业公司虽资源有限,却能提供更纯粹的技术理想主义环境。这种结构性矛盾,或许正是AI创新竞赛中创业公司与大公司比拼的希望。
3月3日,阿里巴巴Qwen团队灵魂人物林俊旸被曝离职。媒体报道称,这位32岁成为阿里最年轻P10级技术高管的天才,曾主导Qwen系列从开源到多模态的全球突破,突然离职或与企业组织架构调整与战略方向冲突有关。这一事件不仅是个体职业选择的转折,更是对当前大公司AI创新困境的深刻折射——当组织规模膨胀至一定程度,流水线KPI与技术理想主义之间的张力或将导致人才流失和创新乏力。这一事件是中国大模型赛道从“技术理想主义”向”商业化重工业”的关键转折点之一。

林俊旸
接替林俊旸的是今年初刚加入阿里的前DeepMind高级资深研究员周浩(Hao Zhou)。两人的背景反差极具代表性。
林俊旸,北大硕士,毕业后通过校招加入阿里巴巴(初入达摩院 NLP 团队),在副总裁周靖人带领下,主导开发了M6万亿参数超大模型、OFA统一模态多任务模型,并从零构建Qwen系列模型,成长为阿里本土培养的最年轻P10。他是Qwen开源生态的灵魂人物,在开源社区、X社区上极具号召力,代表了“快速迭代、极致开源、贴近社区”的打法。
周浩,典型的“硅谷大厂精英”,曾担任谷歌DeepMind高级资深研究员,是多模态视觉基座模型的核心贡献者,更倾向于结构化、建制化的研发体系。
这不仅仅是人事的交替,而是底层路线的冲突。阿里管理层引入周浩,折射出对Qwen过去“野蛮生长”路径的审视。然而,在AI这种极度依赖人才密度和灵魂人物感召力的领域,失去林俊旸这样的“桥梁型人才”,可能意味着Qwen开源社区号召力的断崖式下跌。
大公司"重工业模式"与技术理想主义的结构性冲突
据科技自媒体《晚点》报道,林俊旸离职的直接导火索很可能是因为阿里云将Qwen团队从“垂直整合”模式分拆为“水平分工”的组织架构调整。
谷歌DeepMind、Meta等大公司近两年组织变革后,多采用“CEO指挥+大组织垂直化+小组织水平化”模式(哈萨比斯、扎克伯格直接领导AI业务线),在大部门内实现可协同的“水平分工”,且将具身智能、AlphaFold等特种部队独立出来,并建立贴近市场的AI产品团队,比如搜索引擎、智能工作台、手机智能助手等。OpenAI、Anthropic等创企由于组织规模较小,采用高度“垂直整合”的AI能力中心,并将基础研究(Research)与应用产品(Applied)团队区分开,据说目前OpenAI内部70%的算力都给到基础研究探索各类“不可能的任务”,体现出极强的破局押注决心。
反观阿里巴巴,千问组织的调整本质上反映了大公司创新的系统性困境:当企业规模扩大后,必须通过模块化、标准化和流程化来控制风险与成本,在鼓励技术团队互补协作的同时,也可能削弱自主性和创新敏捷性。
在垂直整合模式下,Qwen团队实现了从预训练、后训练到基础设施的全链路闭环,这种架构允许林俊旸等技术负责人像“英雄式”指挥官一样,根据技术判断快速调整方向。例如2025年10月,林俊旸亲自组建机器人与具身智能团队,这正是大模型从虚拟交互走向实体世界的前沿方向。然而,当组织转向水平分工模式,每个模块都需独立运作并遵循固定KPI,底层技术创新被迫让位于流程合规和全局资源优化。
对比来看,Meta、DeepMind等创业公司或早期AI企业仍普遍采用垂直整合架构。Meta 2026年1月启动的“Compute计划”由CEO扎克伯格直接领导,实现了战略、技术与基础设施的深度协同;谷歌DeepMind的Gemini 3团队同样打破部门壁垒,形成强大合力。这种架构使得创业公司能够更快速地响应技术趋势,如OpenAI在2025年9月至2026年2月的5个月内连续推出4个GPT-5版本,而2026年2月底到3月初,Qwen 团队连续开源了 4 款多模态小模型,并实现了在手机端侧的原生多模态推理。
开源持续投入与大规模商业化的两难选择
林俊旸离职引发的连锁反应——包括Qwen Code负责人惠彬原1月离职、后训练负责人郁博文3月4日离职,以及多位核心架构师的相继离开——暴露了大公司在开源生态与商业化变现间的根本矛盾。
林俊旸的绝对强项在于带领顶尖“极客”建立开源技术威望,这要求高度的技术自主权和对社区反馈的快速响应。就在他离职前的 48 小时(2026 年 3 月 2 日),Qwen 团队完成了“最后的一舞”:密集开源了 Qwen 3.5 系列的 0.8B、2B、4B、9B 四款多模态小模型。尽管这批模型在端侧推理性能上实现了对谷歌的有力反超,但其开源协议的微调却释放了危险信号。与早期完全开放的 Apache 2.0 协议不同,Qwen 3.5 系列开始采用更具约束力的 Qwen Research License,对大规模商用设置了更高的准入门槛。这反映出阿里云正加速从“纯粹开源生态”向“商业闭环套现”的战略重心转移。
GitHub开发者对Qwen3.5的部署问题(如推理进度显示异常)讨论激烈,但阿里分拆后修复进度缓慢,反映出大公司对社区反馈的响应机制已出现断裂。相比之下,创业公司如OpenAI在音频AI领域通过垂直整合的团队架构,能够在两个月内完成技术突破并快速迭代。
阿里开源策略上的保守化,与林俊旸坚持的“极致开源、商用零成本”理念产生了结构性冲突,可能这也最终导致了林俊旸及其麾下核心骨干——Qwen Code 负责人惠彬原、后训练负责人郁博文以及关键贡献者李凯鑫的集体出走。
当企业进入AI产品商业化“深水区”,就需要跨部门调动资源,将模型嵌入企业级解决方案,这与开源社区的去中心化和自由创新精神存在内在冲突。阿里云2025年Q2财报显示,AI+云业务收入增长26%,AI相关产品收入已连续8个季度实现三位数同比增长,但这种增长正从技术突破驱动转向规模化部署驱动。Qwen3.5发布后,阿里云将主要精力投入API服务和标准化模块开发,而非前沿技术探索。
具身智能等前沿领域的战略真空与人才流失
林俊旸离职对阿里Qwen团队的最直接冲击是具身智能等前沿领域的战略中断。他组建的机器人与具身智能团队曾被视为阿里向物理世界AI扩展的核心,但分拆后该团队可能被拆分至不同部门,导致技术方向模糊化。
这一现象折射出大公司在前沿技术布局上的系统性弱点。Anthropic 通过极度扁平的“核心研究员委员会”模式,将预训练、宪法AI对齐与基础设施缝合成一个不可分割的垂直单体,从而在短短数月内以极低的人力损耗交出 Claude 3.5 Sonnet 这种性能怪兽;DeepMind 顶住谷歌内部的“大组织病”重重阻力,通过强制性的跨部门资源整合与人才重组(如 Gemini 与 Genie 项目的端到端融合),努力打破“科学家不碰工程”的宿疾。大公司往往需要经过复杂的审批流程和跨部门协调,导致创新节奏滞后。
人才流失的连锁反应更值得警惕。林俊旸、惠彬原、郁博文等人都是阿里培养的应届生,参与了Qwen模型的早期训练,他们的集体出走表明,大公司已难以长期留住具有创业精神的技术人才。从另一个角度讲,不论硅谷还是北上杭深,大厂高人才密度带来的溢出效应,都成为AI创业的沃土,比如Anthropic从OpenAI独立出来,MiniMax的创始成员来自商汤科技。
从更宏观角度看,林俊旸离职事件反映了AI产业发展阶段的深刻变革。2025-2026年,大模型研发正从依赖少数“天才英雄”的实验室突击,转向比拼组织算力、工程流水线与母体商业变现的“工程创新时代”。在这个新阶段,大公司需要的不再是能在各项学术基准测试中拿第一的研究员,而是能跨部门协作、将核心技术产品化落地的“商业工程师”。当技术理想主义者被迫离开,大公司确实失去了某些关键的技术创新能力,但这也可能是产业成熟化的必然代价。
林俊旸的离职,最终揭示了一个残酷现实:大公司拥有资源、算力和场景优势,却难以维持“天才英雄”的技术自主权;而创业公司虽资源有限,却能提供更纯粹的技术理想主义环境。这种结构性矛盾,或许正是AI创新竞赛中创业公司与大公司比拼的希望。
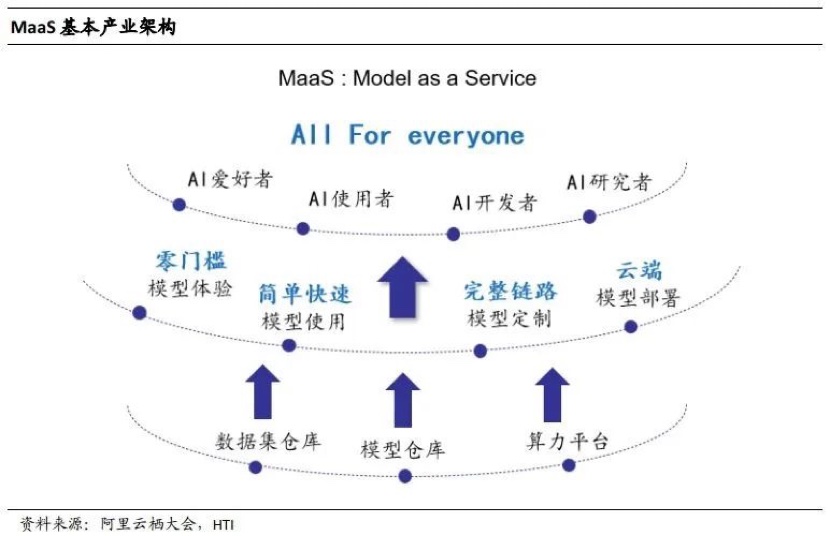
MaaS即“模型即服务”,指以模型为核心提供服务。

阿里云“通义千问”大模型研发负责人周靖人。
“MaaS最底层的含义是要把模型作为重要的生产元素,围绕模型的生命周期设计产品和技术,从模型的开发入手,包括数据处理、特征工程、模型的训练和调优、模型的服务等,提供各种各样的产品和技术。”
阿里云“通义千问”大模型研发负责人周靖人。
MaaS是“Model as a Service”的缩写,即“模型即服务”,指以模型为核心提供服务。2022年11月,任阿里云“通义千问”大模型研发负责人的周靖人在云栖大会上最早提出这个词。此后,在国内伴随着ChatGPT热潮出现的“百模大战”中,这种商业模式广被提及,亚马逊云科技、字节跳动都选择了这条发展路径。
MaaS即“模型即服务”,指以模型为核心提供服务。
在这一场AI大模型热潮中,阿里云非常明显是以云计算服务商的自我认知参与其中。“阿里云的平台非常欢迎第三方模型。”近日,阿里云CTO周靖人在接受澎湃科技(www.thepaper.cn)采访时表示。
在阿里云发起的AI模型社区魔搭中,集聚了180多万AI开发者和900多个AI模型。模型贡献者基本覆盖国内大模型赛道核心玩家,如百川智能、哔哩哔哩、粤港澳大湾区数字经济研究院(IDEA研究院)、澜舟科技、清华大学人工智能研究院、深势科技、浙江大学、智谱AI等。
7月25日晚,阿里云又在其微信公众号上发布声明称,阿里云成为国内首家支持Meta公司的Llama 2全系列训练和部署方案的公司。Llama 2是Meta最新开源的类ChatGPT大语言模型,包括70亿、130亿及700亿参数版本。
“有算力、无模型,不够。有模型,无生态,也不够。发展大模型,算力、模型、生态,缺一不可。”周靖人说。
“让模型的使用更简洁”
“大模型浪潮还处在早期阶段,人人都能感受到技术变革的来临,但对于如何降低大模型的研发门槛、如何实现大模型的落地应用,大家都还没有答案。”周靖人认为,动辄超千亿参数的大模型研发,不是单一的算法问题,也不是靠简单堆积GPU就能实现。“大模型的研发,是囊括了底层算力、网络、存储、大数据、AI框架、AI模型等复杂技术的系统性工程,需要AI和云计算的全栈技术能力。大模型的应用落地更是需要丰厚的生态土壤。”
实际上,多位知情人士对澎湃科技表示,在2021年,任达摩院副院长的周靖人就在内部提及MaaS的概念。
周靖人对澎湃科技解释道,MaaS最底层的含义是要把模型作为重要的生产元素,围绕模型的生命周期设计产品和技术,从模型的开发入手,包括数据处理、特征工程、模型的训练和调优、模型的服务等,提供各种各样的产品和技术。
更简单来说,MaaS最核心的就是让模型的使用更简洁,简单几行代码就可以调用模型。
这就涉及AI模型落地应用的现状,即一个AI模型难以覆盖各行各业的AI应用需求,面对新场景往往需要进行二次开发或优化,否则许多模型难以适配到特定环境应用中。而AI模型定制化门槛较高,同时目前缺乏AI模型开发和使用交流分享的平台。也就是说当开发者遇到相关问题后,无法找到对应的模型服务,也比较难找到人来解答相关问题。
周靖人曾在采访中表示,“最终的目标是,甚至小学生也可以调用模型,能做业务系统的开发。”
“大模型自由市场”
要实现这个目标,就要做一个“大模型自由市场”。
在魔搭(ModelScope)平台上,所有模型生产者都可上传模型,验证模型的技术能力,探索模型的应用场景和商业化模式。从这个意义上说,魔搭社区是个充分开放的大模型自由市场。
魔搭是阿里达摩院与中国计算机学会(CCF)开源发展委员会在2022年联合推出的国内首个AI模型开源社区,把300多个模型开放给中国的AI研究者与团队,涵盖了自然语言处理,视觉、语音、多模态等模型。阿里巴巴在大型语言模型领域的研究主要由达摩院负责,由周靖人主导。
“一个模型的应用,不仅是接入模型,还会涉及到模型的微调、模型的一系列测试等。”7月,周靖人在2023世界人工智能大会上推出新的模型工具ModelScopeGPT(魔搭GPT),目的是有效帮助使用者在海量模型里面找到最合适的模型,“复杂的系统需要多个模型完成联合的任务,今天可以通过这样的一个流程自动化把各种模型融合在一起。”
魔搭GPT(ModelScopeGPT)是一款大模型调用工具,经常被称为agent(智能代理),它能接收用户以自然语言发出的指令,通过“中枢模型”通义千问调用魔搭社区其他的AI模型,大小模型协同完成人类布置的复杂任务。
比如,用户在魔搭GPT的对话框输入任务:“用20字描述一款新的VR(虚拟现实)眼镜,并用女声朗读,随后转成视频。”魔搭GPT会展示整个任务规划过程,先由中枢模型生成一段描述VR眼镜的文案,接着调用语音生成模型,生成语音并用女声念出,最后调用视频生成模型,输出最终的视频内容。过程中,魔搭GPT先后调用了一大二小3个模型。
目前从全球来看,MaaS的订阅制收费早已经开始。根据海通证券研报总结:OpenAI在2月1日正式官宣ChatGPT Plus试点订阅计划。此外,嵌入其他产品获得引流式收入也是模式之一,例如微软推出高级付费版Microsoft Teams Premium,订阅者可享用“智能回顾”功能,用以提供自动生成的会议记录、推荐任务和个性化标亮。其它收费模式包括不同模型对不同客户需求和客户定价,客户要求越高,模型越好,收费也将越高。
周靖人认为,大模型的研发不应该是一场少数机构的竞赛,而应该通过大小模型的协同进化走向更高级的应用,尤其是适应中国本土需求的应用。

国家标准委指导的国家人工智能标准化总体组宣布我国首个大模型标准化专题组组长。

科大讯飞研究院院长刘聪被聘为国家人工智能标准化总体组大模型专题组联合组长的聘书。图片来源:科大讯飞

·上海人工智能实验室与科大讯飞、华为、阿里、百度等企业联合担任我国首个大模型标准化专题组组长。在2023世界人工智能大会上,国家人工智能标准化总体组宣布正式启动大模型测试国家标准制订。
7月7日,在2023世界人工智能大会“共话标准,驱动产业——生成式人工智能标准化分论坛”上,国家标准委指导的国家人工智能标准化总体组宣布我国首个大模型标准化专题组组长,由上海人工智能实验室与科大讯飞、华为、阿里、百度等企业联合担任,现场进行了证书颁发并正式启动大模型测试国家标准制订。
国家标准委指导的国家人工智能标准化总体组宣布我国首个大模型标准化专题组组长。
公开资料显示,今年5月,国家人工智能标准化总体组正式启动大模型专题组相关工作,以推动大模型国家标准化工作的开展。大模型专题组将承担大模型标准化制订工作,目的是推动大模型技术和标准化的实践结合,促进人工智能产业健康发展。
国家人工智能标准化总体组官方微信公众号显示,大模型专题组组长、副组长申报条件为:
1、由总体组成员单位推荐单位内部大模领域专家进行申报,申报人需具有中华人民共和国国籍,政治思想素质较高,遵纪守法,具有良好的科学道德、诚信记录、职业操守和较强的责任心。
2、在大模型理论研究和产业应用等方面具有较高专业水平,熟悉该领域国际前沿科技发展态势、法规制度与标准规范等。牵头起草过国际、国家或行业标准,具有在主要国际组织或标委会中有大模型标准化相关工作经验的优先。
3、原则上不超过65周岁,具有能够适应和完成相关工作的身体条件。
澎湃科技(www.thepaper.cn)从科大讯飞了解到,科大讯飞研究院院长刘聪被聘为国家人工智能标准化总体组大模型专题组联合组长,组长聘期为三年。
360集团方面告诉中国证券报,身为大模型专题组组长单位,公司将积极参与工作组工作,发挥自身实践和经验优势,参与大模型测试国家标准制订。
科大讯飞研究院院长刘聪被聘为国家人工智能标准化总体组大模型专题组联合组长的聘书。图片来源:科大讯飞
根据国家人工智能标准化总体组官方微信公众号,对有关大模型标准化研究选题建议要求为:
1. 研究选题应注重结合国际态式、我国国情和实际工作需求,重点围绕大模型软硬件底座、关键技术、产业应用等重点领域的突出问题,具备孵化标准或指导性技术文件的可能性。
2. 研究选题应具有明确的研究目标、研究任务和较强的创新价值或应用价值,文字表述科学、清晰、简洁。