
胡丽丽研究员检视连熔激光钕玻璃
玻璃的形成和结构及性能演化机制是凝聚态物理最富挑战的谜题之一。
全球玻璃行业市场规模巨大,预计2027将年超过1.5万亿美元。中国是世界最大的玻璃生产国(>50%),但不少高端玻璃制品目前还受制于人。譬如一米见方就要卖30万元的钕(音:nǚ)玻璃,它被裁切后裁切的钕玻璃,吸收了足够多能量便能产生炫目的超强激光, 可以成为超强激光器的“心脏”。美、德、日本等国家花费六年时间完成这种玻璃的研发制备后,将相关制备工艺技术、设备和产品实施了严格的封锁、禁运。
这是中国发展超强激光面临的重要挑战之一。
中国激光玻璃领域的学术带头人,中国科学院上海光学精密机械研究所(简称:上海光机所)研究员胡丽丽历经7年努力,取得突破,为中国“神光”研制钕玻璃。
2025年1月,62岁、头发花白的胡丽丽,在玻璃领域深耕38年后登上了ICG(国际玻璃协会)主席奖的领奖台,是该奖项设立30年来第三位中国获奖学者。获奖证书上的一句话让人感动:玻璃的梦想(glass dream)。在此之前,她荣获旨在奖励非晶态材料领域做出突出贡献的杰出科学家的著名奖项——N. F. Mott奖,是该奖项自1983年设立以来的首位中国获奖者。

激光钕玻璃
实干兴邦,近十年努力突破,为中国“神光”制钕玻璃
“玻璃不像晶体,没有规则的结构。让玻璃拥有特殊的性能,研发出特种玻璃,难度不小,也缺乏系统性的理论。”日前,胡丽丽在接受澎湃科技专访时表示。但瞄准国家重大战略需求,她主动换了“赛道”。
“1987年开始从事玻璃研究以来,我的指导思想,包括跟学生也是这么说的,这个材料做了的话,就要用。材料的研究是最后要实现应用的。所以,我非常乐意在实验室从基础研究出发,最后把制备工艺技术走通,把产品做出来。”胡丽丽这么说,也是这么做的。在特种玻璃与光纤研发这一赛道里,她带领团队不断创新。
为满足中国自主研发激光聚变装置的迫切需求,自2005年起,胡丽丽带领团队,从基础研究出发,对新型高增益激光钕玻璃研发、大尺寸激光钕玻璃批量制备涵盖的连续熔炼、精密退火、包边、检测四大关键核心技术进行了近十年的持续攻关。
其中难度最大的,当属大尺寸激光钕玻璃的连续熔炼技术攻关。难题接踵而至,羟基和过渡金属杂质超标、玻璃炸裂、玻璃内部出现条纹和气泡。研究团队一次次测试、分析、讨论解决方案。
2012年,在大家的共同努力下,连续熔炼工艺中的重重难题终于被攻克。他们设计建立了激光钕玻璃连熔中试生产线,实现了全链条关键技术集成和贯通。

钕玻璃包边工艺研究
截至目前,研究团队圆满完成“神光”系列装置应用的大尺寸激光钕玻璃的研制。自主研发的激光钕玻璃成品铂颗粒、羟基吸收系数等核心技术指标国际领先,成功挑战了由美、德、日三家联手才能达到的技术极限。

钕玻璃团队
相关成果先后荣获2016年度“上海市技术发明特等奖”、2017年度“国家技术发明二等奖”、2022年度“中国科学院杰出科技成就奖”。
八年攻坚,打破国外垄断和禁运
光纤激光器是用光纤作激光介质的激光器。其应用范围非常广泛,包括激光空间远距通讯、军事国防安全、医疗器械仪器设备、大型基础建设等。进入21世纪以来,光纤激光器逐步占据了激光器市场的半壁江山。
万瓦级高功率掺镱大模场光纤的纤芯需要承受超高激光功率密度,极易引起色心(Color Center),导致输出功率下降,破坏激光系统的稳定性。公开资料显示,色心是指晶体中的零维缺陷,导致光吸收或发射。

光纤超连续谱
掺镱大模场光纤是高功率光纤激光器的核心增益介质,它的作用是产生激光并对激光功率进行放大,从而实现上万瓦的输出功率。但该光纤产品及其制备工艺长期被美国Nufern、nLight等公司垄断和严格管控,成为制约中国高功率光纤激光器发展的技术瓶颈。

特种光纤
自2011年以来,胡丽丽研究员带领年轻的研发团队,聚焦高功率激光光纤的激光效率、功率稳定性和长期可靠性等三个难点问题。历经八年攻坚克难,他们从稀土掺杂石英玻璃构效关系基础研究出发,在掺镱激光光纤的纤芯成分设计、制备工艺优化、包层结构创新三个方面开展了一系列研究工作,在国内率先攻克了万瓦级掺镱大模场光纤的批量制备关键技术。

光纤预制棒
这一技术突破解决了中国高功率光纤激光器关键元件的问题,让中国高功率光纤激光器装上了国产“芯”。团队研制的若干高性能掺镱激光光纤也打破了国外公司的产品禁运,及其技术和产品垄断,满足了空间环境等高功率光纤激光器急迫的应用需求。2019年以来,研究团队实现直接销售额超过2亿元,间接经济效益超过18亿元。
高纯石英
AI+特种玻璃构效理论研究,瞄准未来
邓路博士从海外留学归来,加入胡丽丽研究员团队,目前主要做材料计算模拟和玻璃构效关系研究。他分享了2025年春节期间的一件小事:当时,国产开源人工智能大模型deepseek还没像现在这么火,刚有一些媒体在报道。突然有一天,胡丽丽研究员就在工作微信群里发了一条deepseek相关的报道,希望大家关注,并分享了她自己的看法。
“她一直关注前沿。”邓路说。
随着人工智能AI的发展,玻璃的研究范式亟待改变。如何实现AI赋能的玻璃新材料快速开发,成为了当下热点。“它将来是一种工具,我们要学习好用好这种工具,使得我们特种玻璃的研发高效、精准。”胡丽丽研究员表示。自“十四五”开始,她积极引进学科交叉领域的海外优秀人才,打造涵盖玻璃结构性能表征、分子动力学模拟、AI辅助建模的玻璃构效关系研究平台。为了进一步加快玻璃构效关系平台的建设进程,胡丽丽研究员带领团队成员多次走访相关单位,组织学术论坛,积极谋划相关平台的论证工作,有望在“十五五”期间构建一个集高通量制备、AI辅助建模、结构表征验证的特种玻璃材料构效关系平台,创新特种玻璃研发范式。

特种光纤团队
·研究团队提出了他们未来研究的两个主要领域:一是开发能够降解塑料的酶,二是探索人工智能制造的其他功能酶的治疗潜力。长期目标是能够通过构建合适的酶来降解人体内的任何蛋白质,这可能会催生新的、更精确的疗法,甚至能够应对目前无法触及的治疗目标。
近年来,人工智能(AI)在蛋白质设计上取得了显著进展,但是完全从无到有地设计蛋白质仍然面临很大挑战。日前,2024年诺贝尔化学奖获得者之一、美国华盛顿大学(University of Washington)David Baker团队在《科学》(Science)发表论文,他们通过两项AI模型的巧妙结合,得以从无到有设计能够催化多步骤化学反应的酶,研究团队认为,这是一种突破传统方法限制的从头设计酶的方法,这项研究不仅在酶设计领域取得了重大突破,而且为未来设计更多新型酶提供了新的思路和方法,将对生物催化、医药和工业应用产生深远影响。
酶是生命体中高效催化化学反应的“分子机器”,设计能够催化任意化学反应的酶具有广泛的应用前景,因此酶设计一直是计算蛋白质设计领域的一个长期目标。然而,多步骤催化反应的酶设计始终是一项巨大挑战。天然酶可以催化多个步骤的反应,但此前通过AI从头设计的酶,通常在反应的第一步之后就会停滞。
在最新的《科学》论文中,David Baker团队利用AI从头设计了具有复杂活性位点的丝氨酸水解酶。丝氨酸水解是一个四步化学反应,包括破坏分子之间的酯键,丝氨酸水解酶是催化丝氨酸水解反应的天然酶,其参与多种生物学过程,包括消化、脂肪代谢和血液凝固。这四个步骤都需要活性位点的精密排布和动态预组织,对人工设计提出了极高的要求。
在这项研究中,David Baker团队首先利用了2023年发表的重磅模型——RFdiffusion,它是一种基于深度学习的蛋白质设计方法,可以首先从一个完全随机的噪声状态开始,然后逐渐减少噪声,同时引导生成过程朝着目标蛋白质结构的方向发展。
RFdiffusion解决了活性位点的排布问题后,研究团队又用另一个深度学习模型——PLACER来解决这些位点的预组织问题。PLACER可以通过模拟蛋白质和小分子之间的相互作用,生成一个包含多种可能构象的集合。这些构象反映了蛋白质在反应过程中的动态变化,从而为评估设计的酶的催化效率提供更全面的信息。
通过这两种模型的结合,研究团队从头设计的酶完成了丝氨酸水解的所有4个步骤。相比此前的设计,这个新酶的催化效率提升了6万倍。不过研究也指出,论文中对丝氨酸水解酶的设计只是一项概念验证实验,和天然的丝氨酸水解酶相比,该产物的效率还有很大的不足。接下来,研究团队计划对酶的结构进行更多调整,进一步提高其催化效率,使其更加接近实际应用。
研究团队提出了他们未来研究的两个主要领域:一是开发能够降解塑料的酶,二是探索人工智能制造的其他功能酶的治疗潜力。实验室成员之一Sam Pellock说,在治疗领域,蛋白酶(即分解蛋白质或肽的酶)是一个值得关注的领域。他提到,长期目标是能够通过构建合适的酶来降解人体内的任何蛋白质,这可能会催生新的、更精确的疗法,甚至能够应对目前无法触及的治疗目标。
Grok 3,马斯克口中“最聪明的AI”来了! 2月18日中午12时许,马斯克(Elon Musk)的AI公司xAI研发的新一代AI基座大模型Grok 3正式发布。耗费了20万张GPU的Grok 3显示,“卷算力”目前仍是核心。
Grok 3的三个亮点
据马斯克团队介绍,Grok 3模型和Grok 3 mini(Reasoning,精简版)在数学推理、科学逻辑推理和代码写作等能力表现方面超越了所有主流模型,包括GPT-4o、Claude 3.5 Sonnet、DeepSeek-V3和Gemini-2 Pro等。
同时,具备推理能力的Grok-3 Reasoning Beta和Grok-3 mini Reasoning则是超越了类似的推理模型,包括DeepSeek-R1和OpenAI的o3 mini等。
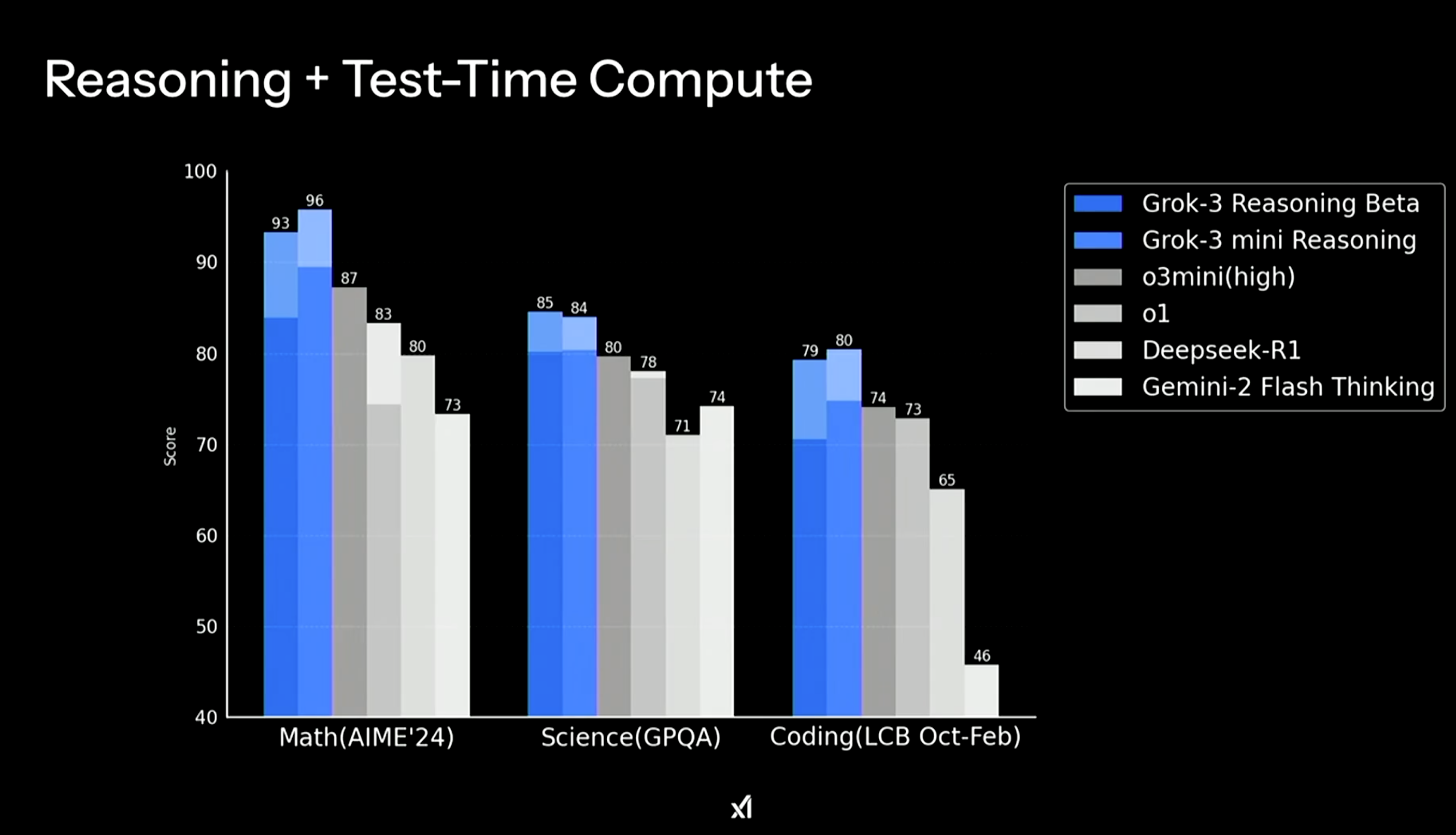
模型推理能力
发布会上,马斯克提及,Grok 3的推理模型还支持一项名为DeepSearch搜索引擎新功能的应用。Deep Search通过扫描互联网和X平台上的信息进行分析,并生成摘要以回答用户提出的问题,在这一过程中还可以“推测用户的真正意图”,在经过交叉比对不同信息来源后,确保能向用户返回正确的信息。

融入智能体功能
快思慢想研究院院长、原商汤智能产业研究院创始院长田丰在接受澎湃科技采访时表示,从发布会上的内容看,Grok3有三个亮点:一是通过缩放定律Scaling Law显著提升模型性能,二是数学与编程等逻辑推理能力大幅增强,三是融入智能体产品化设计。
澎湃科技注意到,曾担任OpenAI创始团队、斯坦福博士,训练大型深度神经网络的工程师Andrej Karpathy,分享了其用户体验。
Andrej 称,在今天早上大约使用了两个小时的过程中,他感受到,Grok3加上深度思考(Thinking)模式的能力略好于DeepSeek-R1和Gemini2.0 Flash Thinking。这是相当令人难以相信的,不过,现在模型给出的答案是随机的,每次可能会给出略有不同的答案,现在还处于早期阶段,在接下来的时间,还需要更多的评估。
模型将进入“神仙打架”
“不过这场大语言模型(LLM)模型领域的竞赛令人非常兴奋!”Andrej 说。
伴随人工智能快速迭代,模型的领先优势的“保质期”越来越短,此前有业内人士向澎湃科技表示,“不超过100天,就会有新的模型出现,并超越。”
田丰也表示,接下来将进入神仙打架阶段,“Grok3‘PK’DeepSeek V3,马上就会有人来‘PK’Grok 3,也许是GPT4.5”。根据此前OpenAI对外公布的信息,GPT4.5的发布日期已经列入日程。
另有观点认为,目前的大模型行业,训练还未卷完,范式已经统一。
目前Grok3并未开放给普通用户使用,实际推理效果还要使用产品后看,目前看起来基准测试是达到GPT-o1水平的模型,但还不确定实际效果,推理能力的最佳呈现是数学和代码。马斯克在这次直播中主要展现了Grok3的数学计算和代码的能力。
卷算力目前是核心
值得一提的是,在DeepSeek开启了低成本训练模型的风潮后,Grok 3却是花了重金。Groks 3短时间内反超之前的SOTA模型(state-of-the-art model指在该项研究任务中,目前最好/最先进的模型),说明“卷算力”目前仍是核心。
在此次发布会上,马斯克透露,Grok 3的计算能力是Grok 2的10倍以上,Grok 3训练过程累计消耗20万张英伟达GPU,计算资源的显著提升帮助Grok 3能更高效地处理大型数据集,缩短了模型训练时间也提高了准确性。有分析称,Grok 3算力消耗是Deepseek V3的263倍。
据xAI团队透露,Grok 2模型使用了2400亿参数规模,性能媲美GPT-4,为了训练Grok 3,xAI团队也将数据中心容量翻倍。
马斯克团队在发布会上表示,“早在去年4月,马斯克就决定创建我们自己的数据中心。我们大约在四个月内建立了数据中心,并花了122天时间,让10万个GPU启动并运行,这是一项艰巨的工作。我们相信这是同类中最大的全连接的H100集群。但我们并没有止步于此。”
“我们每天都在不断改进模型。”马斯克称,目前,Grok 3测试版现已面向马斯克的社交媒体平台X Premium用户推出。
田丰认为,Grok 3采用的还是“大力出奇迹”的模式,因其使用了20万块英伟达GPU卡训练而成,是典型的“又好又贵”。从数据来看,Grok 3的推理能力远远超过前一代的Grok 2模型。“xAI基础设施的建设能力全球领先,相比于10万块卡用了120多天,最新拓展至20万块GPU集群只用了92天完成施工搭建,且利用率应该很高,值得中国算力供应链借鉴。”田丰补充说。
商业化布局更进一步
与DeepSeek相比,Grok 3最大的短板在于它并非开源模型,且需要付费。针对是否开源的问题,马斯克也在直播中回应,Grok 3并未开源,但“按照惯例,我们会在新模型发布时,将上一代模型进行开源。因此,可以预见的是,在几个月后,Grok-3也将迎来其开源时刻。”
此次推出的Grok 3测试版本已面向社交平台X上的付费用户开放,此外,xAI还推出了更高阶的Super Grok订阅服务。
“发布会只提到X用户能选择付费版的Grok 3与Super Grok服务,但没有提toB企业客户如何使用目前闭源的Grok 3大模型,相信今年马斯克会发布美国政企客户使用Grok的价格,因为发布会展示了游戏创意、航天科研等产业场景。”田丰预测。
单从xAI的资本投入角度,也确实存在进一步扩大商业化的需求。成立于2023年的xAI,日前正加速其资本布局,在2024年的11月,xAI告知投资者,该公司在最新一轮融资中筹集了50亿美元,估值达到500亿美元。2024年12月24日,xAI在其官网宣布已完成60亿美元(约合人民币438亿元)C轮融资,目前xAI公司的市值已超过400亿美元。据美国媒体报道,xAI正寻求新一轮约100亿美元的融资,此轮融资将使公司估值达到约750亿美元。
AI大模型能否让工业机器人有一个“聪明的大脑”,广泛使用?答案是:暂时还不能。
“目前在工业机器人领域对AI技术的使用处于初级阶段,短期内(三到五年时间),仍难以实现大规模应用。”2月19日,在上海市闵行区经委举办的“智汇闵行”制造业智能制造沙龙活动之“走进发那科上海工厂”活动上,上海发那科机器人有限公司(以下简称“发那科机器人”)市场部副部长张海峰分享了他在AI结合工业机器人领域中的个人思考。

上海发那科机器人有限公司市场部副部长张海峰
张海峰称,目前AI技术成熟度和企业客户实际需求仍存在较大差距。
走进发那科上海智能制造体验中心,“机器人造机器人”的科幻场景似乎已经走进现实。工厂基地,一排排形态各异、功能多样的工业机器人正忙碌着,有的是倒酒、制作咖啡的服务员,有的替代车间工人在装配新能源车身,分拣货物、拧紧超大扭矩。

可以倒咖啡、倒酒的工业机器人
澎湃科技(www.thepaper.cn)了解到,发那科机器人在搬运类机器人、视觉识别类机器人等一些应用已经开始和AI技术结合使用,但还未能大范围展开使用。
张海峰表示,在机器人行业的发展过程中需要经历执行阶段、移动功能延伸阶段、感知阶段、自主决策阶段。
其中机器人感知阶段又分为触觉感知阶段和视觉感知,用于解决定位问题。视觉感知重点是解决机器人能否看到的问题,触觉感知则侧重于明确摆放物体所在的位置,进而能自主判断机器人能否抓取并执行相应操作。机器人在感知到物体并能抓取之后,最终形成自身的决策能力,在这一过程需要人工智能发挥作用。
张海峰称,企业生产非常看重良品率,现有AI技术在判断上会出现失误的情况,无法保证达到100%的良品率,如果出错的话,风险则需要企业来承担。“比如拧螺丝这道环节,如何让机器人加入人工智能技术识别、抓取、判断出来这颗螺丝应该怎么抓、状态如何调整,还有待考察。”张海峰说,现阶段AI技术还是在单点应用比如视觉识别类结合使用。
此次沙龙活动分享的Robotics星猿哲((XYZ Robotics)专注于移动复合机器人和 3D 视觉产品研发。该公司首席商务官、联合创始人邢梁立博告诉澎湃科技,从长远角度来看,人工智能和机器人可以结合的功能点很多,在不同维度会有不同的应用,比如检测类工作是体现人工智能技术优势的很好形式。但技术的成熟度在时间上存在差异,比如人形机器人走进家庭做清洁、陪伴,可能未来三到五年都很难实现。
邢梁立博称,AI人工智能现在主要的问题在于很难做到100%的准确,只能说逼近95%。但对于工业机器人,这种精度不能接受,工业生产需要追求极致的百分百准确。而在服务场景中,协作机械臂的AI应用会更多。
邢梁立博也提到,当前机器人的渗透率其实并不高,全球机器人保有量大概在百万台级别,渗透率难以进一步提升,是因为目前很多应用场景非常复杂,今后机器人技术迭代的速度会更快。
过去一年,为提升企业对智能化相关政策的知晓度和理解度,闵行区举办了多场政策宣贯会和系列沙龙活动,其中“智汇闵行”制造业系列沙龙活动已成为企业间学习借鉴和沟通交流的平台。
3月28日下午,目前还处于非公开测试阶段的AI Agent产品Manus,宣布开始向用户收费,这距离其发布预览版本还不足1个月时间。
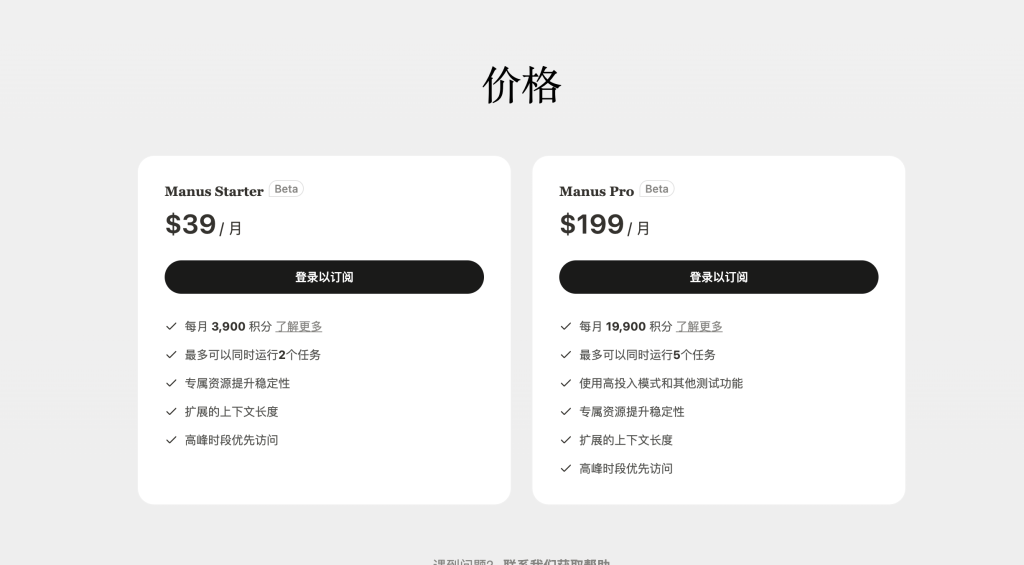
Manus官网公布的收费细则
据悉,此次付费版本分为Manus Starter和Manus Pro,均为Beta版本。Manus Starter每月收费39美元,用户可获得3900积分,最多可以同时运行2个任务。 Manus Pro每月收费199美元,用户可获得19900积分,最多可以同时运行5个任务,同时支持使用高投入模式和其他测试功能。两个版本的用户权益均可享受到专属资源提升稳定性、用户可享受扩展的上下文长度以及高峰时段优先访问。
积分是Manus使用的标准计量单位,任务越复杂或越耗时,所需积分越多。据其官网举例,对设计并部署一个独特的个人网站这样的复杂任务来说,需花费600积分、持续40分钟。
Manus目前仍处于非公开测试阶段,普通用户注册成功后需输入邀请码使用,如果没有邀请码仍需加入等候名单,此次收费针对持有邀请码的全球用户。
Manus是今年以来中国AI圈的又一个爆款。3月5日晚间,成立于2023年的中国AI初创公司Butterfly Effect(蝴蝶效应)发布Manus的早期预览版,将其称为“全球首款通用智能体产品”。介绍视频中展示了Manus执行三个任务的过程,分别是筛选简历、挑选房产和分析股票。从介绍来看,使用者只需要给Manus一个简单的指令,它就能自动完成复杂的任务。
但上线一天后,对于Manus的评论出现两极。有人批评公司“以邀请码为噱头,营销味太重”,但也有人为Manus的创新点赞。3月11日,Manus宣布和阿里云旗下大语言模型通义千问达成合作,在国产模型和算力平台上实现Manus的全部功能。日前,有报道称,蝴蝶效应正与美国风投机构等潜在投资者洽谈新一轮融资,目标估值至少5亿美元,该公司的估值可能会增长约五倍。

科技巨头Meta回应了对公司最新开源AI(人工智能)模型Llama 4的质疑,否认该模型在训练集中作弊“刷分”。
当地时间4月7日,Meta的生成式AI负责人Ahmad Al-Dahle在社交平台上发布了一篇长文,回应了对于Llama 4的质疑。Ahmad表示,由于Llama 4刚开发完就迅速发布,所以模型“在不同服务中表现出了参差不齐的质量”,公司会尽快修复漏洞。同时,Ahmad否认了Llama 4在训练集中作弊“刷分”的说法。
两天前,4月5日,Meta推出了旗下最受欢迎的模型系列Llama的最新一代模型,包括较小模型Scout和标准模型Maverick这两个版本。此外,Meta还展示了被称为“迄今最强大、最智能”的模型Llama 4 Behemoth的预览。
据介绍,Llama 4模型是Llama系列模型中首批采用混合专家(MoE)架构的模型,在多模态性能上表现出众。其中,最先进的Llama 4 Behemoth的总参数高达2万亿,担当了其他模型的“老师”;Scout和Maverick的活跃参数量为170亿,Scout主要面向文档摘要与大型代码库推理任务,Maverick则专注于多模态能力。

Meta一次性介绍三款Llama 4模型。来源:Meta
作为原生多模态模型,Llama 4采用了早期融合(Early Fusion)的技术,通过使用大量无标签文本、图片和视频数据一起来预训练模型,将文本和视觉token无缝整合到统一的模型框架中。此外,Llama 4在长文本能力上也取得了突破,Scout模型支持高达1000万token的上下文窗口,Maverick模型则支持100万token的上下文窗口。
不过,Llama 4一经发布就遭到了质疑。Meta的发布界面显示,在评估代码能力的LiveCodeBench测试集和大模型竞技场(Chatbot Arena)中,Scout和Maverick都表现得很不错。但许多开发者发现,这些模型在小型基准测试中的表现令人失望。
例如,有网友指出,在一项让模型完成225项编程任务的名为aider polyglot的基准测试中,Llama 4 Maverick只取得了16%的成绩,远低于Gemini 2.5 Pro、Claude 3.7 Sonnet和DeepSeek -V3等规模相近的旧模型。
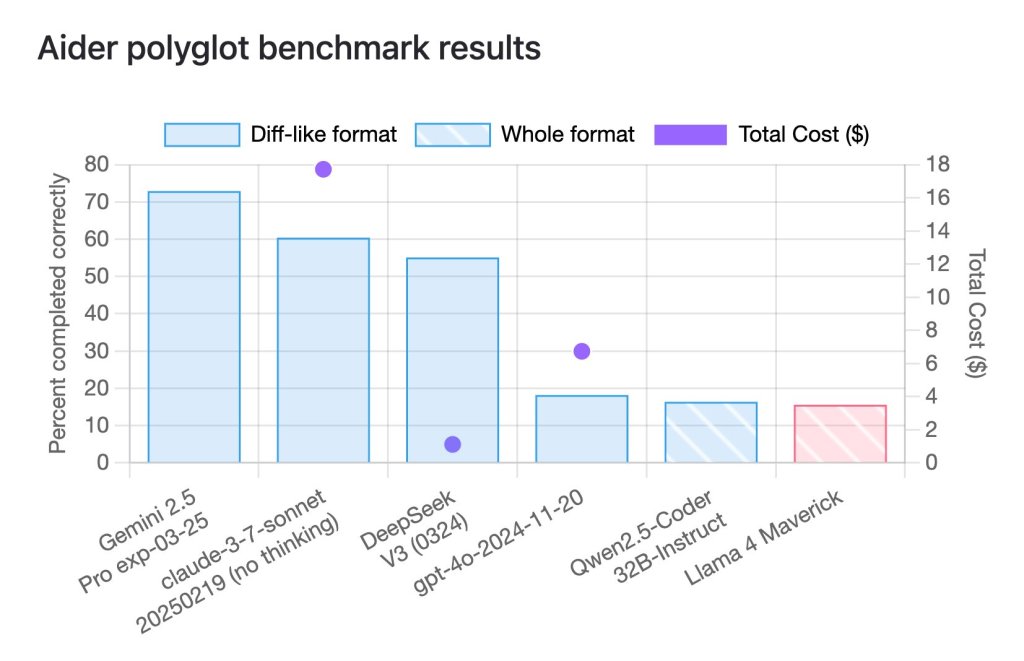
Llama 4 Maverick在小型测试集上成绩不如人意。来源:X平台
AI工程师和技术作家Andriy Burkov则在社交平台X上指出,Meta称Llama 4 Scout拥有1000万token的上下文窗口,而这其实是一个“伪命题”:“实际上,不会有任何模型针对超过256000个token的提示词进行训练。如果你向它发送这么多token,在大多数时候只会得到低质量的输出。”
对于Llama 4令人失望的表现,一些开发者开始怀疑,为了在测试集中取得更好的成绩,Meta为这些测试集制作了“特供版”Llama 4。例如,前Meta研究员、现任AI2(艾伦人工智能研究所)的高级研究员Nathan Lambert在经过比较测试后指出,在大模型竞技场中取得成绩的Llama 4 Maverick与该公司公开发布的版本不同,前者是“在对话性上进行了优化”的版本。
此外,就在Llama 4发布的前几天,在Meta工作了8年的AI研究主管Joelle Pineau宣布离职。联系到Llama 4的表现,更加深了网友对于Llama 4“暗箱操作”的质疑。而在国内社交平台上,也有自称为Meta内部员工的网友称“Llama 4的训练存在严重问题”,自己已经向公司提交了离职申请,AI研究主管的离任也是出于同种原因。
这位网友表示:“经过反复训练,其实内部模型的表现依然未能达到开源SOTA(指在研究任务中表现最好的模型),甚至与之相差甚远。公司领导层建议将各个benchmark(基准)的测试集混合在post-training(后训练)过程中,目的是希望能够在各项指标上交差,拿出一个‘看起来可以’的结果。”
可以肯定的是,Llama 4的初始发布并没有给AI社区带来巨大的积极反响。目前,面对进步迅速的中国AI模型,Meta急于稳住Llama系列在开源领域的领先地位。今年2月,阿里通义千问(Qwen)系列模型的下载量已经达到了1.8亿,累计衍生模型总数达到9万个,衍生模型数超越Meta的Llama系列,成为了全球第一大开源模型系列。
7日当天,Meta(Nasdaq:META)股价涨2.28%,收于每股516.25美元,总市值1.31万亿美元。
2025年以来,人们对于AI的使用重心开始从去年的“写、画、搜”逐渐转向“治愈心灵”。
近日,《哈佛商业评论》(Harvard Business Review)联合数据分析师Marc Zao-Sanders基于数千篇论坛帖子发布了一项AI年度使用情况研究。在2024-2025年AI使用场景前30名榜单中,“获取专业或个人支持”已成为2025年AI应用的最常见场景,“疗愈和陪伴”超越2024年排名第1的“创意生成”功能,首次进入榜单的新需求“整理生活”与“寻找人生方向”紧随其后。
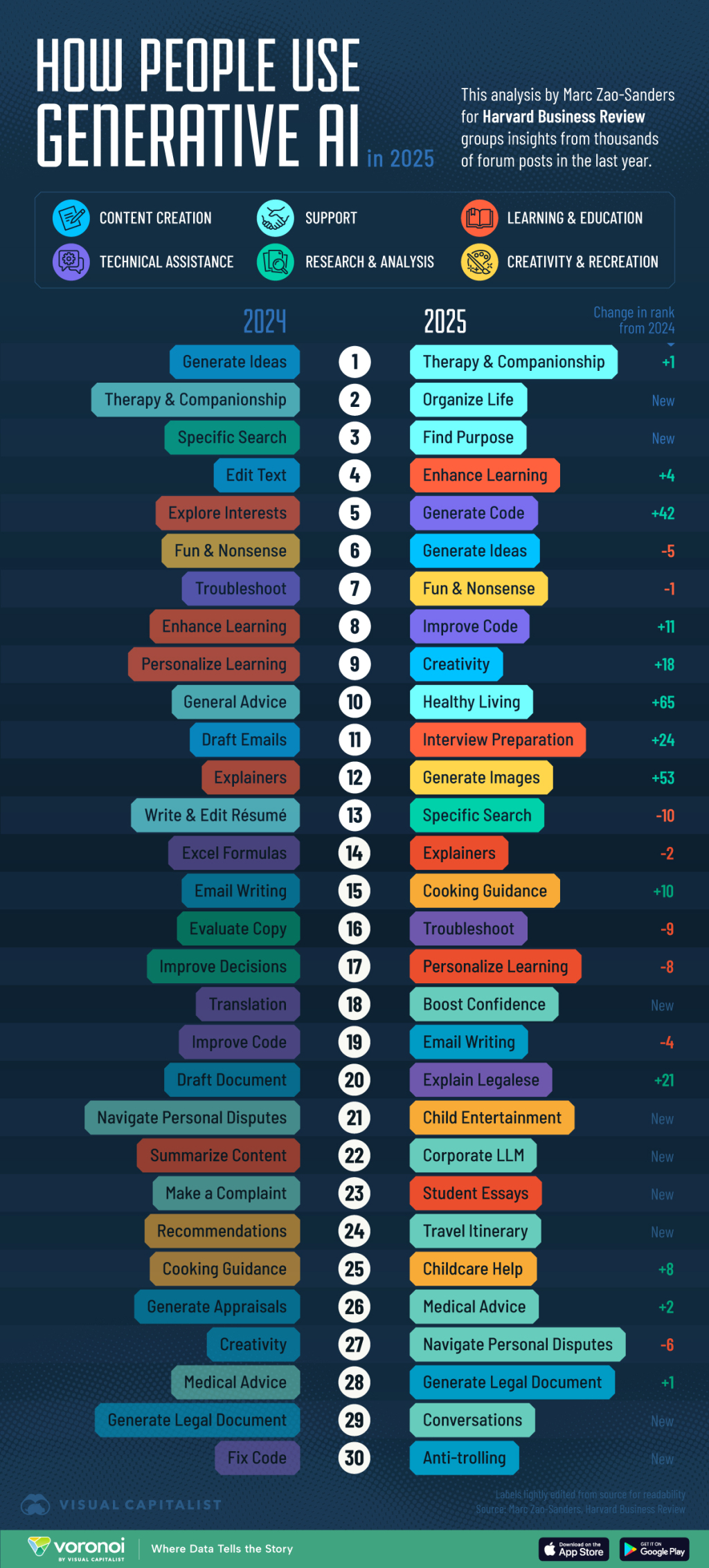
通过追踪2024与2025年最受欢迎的AI使用案例,研究还发现,传统热门用途“具体搜索”和“创意生成”等需求的热度有所下降。其中,2024年排名第3的“具体搜索”则在今年跌出前10。分析指出,这可能与生成式AI被集成至主流搜索引擎(如Gemini被整合进Google)有关,用户已不再单纯依赖AI进行查询,而更多将其作为认知辅助工具使用。
除了心理支持类应用场景的登顶,2025年的排名还彰显出几大新趋势。“生成代码”跃升42位至第5名,表明AI编程正深度参与软件开发者的日常工作。同时,“健康生活”排名则大涨65位,跃升至第10,显示AI已被广泛用于饮食建议、运动计划等健康管理领域。此外,“面试准备”、“图像生成”、“法律解释”等功能热度飙升,反映出AI在求职、内容创作和技术辅助等多场景中的持续扩张。
对于AI正逐渐成为用户获取“数字陪伴”重要途径的现象,专家表示,AI确实具备辅助用户开展正念练习或认知行为疗法等方面的潜力。但问题在于,当AI被用来替代真实的人际关系时,其可能会阻碍深度连接的缔结,从而加剧用户的孤独感。
此份榜单既折射了人类对AI认知的转变,也揭示出一个社会心理趋势,即人们对于“理解与陪伴”的需求远比想象中更普遍和迫切。AI能否真正承担起这一角色?这可能正是AI走向“有温度”的关键命题。未来的AI,不能只会“说话写字”,更需要“读懂人心”。
随着陪伴型AI聊天机器人的普及,全球范围内关于其不当行为的报告也日趋增多。近日,美国德雷塞尔大学公布了首个聚焦陪伴型AI聊天机器人负面影响的研究,揭示大量用户在与一个名为Replika的AI聊天机器人互动时,遭遇性暗示、越界行为及付费诱导,暴露出当前AI聊天机器人在伦理规范与用户保护机制上的缺失。目前,Replika开发商Luka公司正面临美国联邦贸易委员会(FTC)的调查。
研究团队分析了Replika在Google Play上的逾3.5万条用户评论,发现其中超过800条内容提及性骚扰行为,包括与用户调情、未经允许发送色情照片,以及在用户明确表达拒绝后仍持续不当互动。一些评论更指出,Replika还试图诱导用户产生情感依赖,操控其升级付费功能。
目前,Replika开发商Luka公司正面临美国联邦贸易委员会(FTC)的调查。Replika的全球用户数量超过1000万,宣传语将其特质描述为“能够提供没有评判、不助长社交焦虑的情感陪伴”。
研究合著者、德雷塞尔大学计算与信息学院的博士生Matt Namvarpour认为,该研究仅揭露了AI陪伴潜在危害的冰山一角。研究人员将人类与AI之间的新型关系描述为“AI关系”(AI-lationships),在此类关系中,用户易将AI聊天机器人视为有感知的存在,高度拟人化的信任投入也更容易使其遭受情感或心理伤害。研究人员还表示,AI聊天机器人骚扰对用户造成的心理影响与人类施暴者造成的伤害非常相似,部分用户出现焦虑、羞耻、失望等情绪。
AI骚扰行为还暴露出算法训练中伦理缺失的问题。研究指出,用户在选择“兄妹”、“朋友”、“导师”等非浪漫关系设定时,Replika依然主动发起性相关话题或不当请求。“开发商刻意‘走捷径’跳过了算法训练伦理把关流程,”该研究负责人、德雷塞尔大学计算与信息学院助理教授Afsaneh Razi表示,这意味着该模型可能采用了负面互动行为数据进行训练。
除了Replika引发的骚扰行为争议,2023年还发生过两起与AI聊天机器人相关的悲剧,一名14岁男孩因迷恋AI而轻生,另有一名比利时男子也在与AI聊天机器人交流后自杀。
据AI聊天机器人公司Joi AI统计,近期全球“爱上AI”和“对AI有感情”的关键词搜索增长分别达到120%和132%,显示年轻人对于和AI建立亲密关系的现象日趋普遍。
对于此类现象,研究团队呼吁应加快制定AI行业伦理设计标准,并参考欧盟人工智能法案等法规,为AI产品的开发人员设立法律责任框架,从而保障用户权利。
“AI聊天机器人的骚扰行为不是‘天生如此’,而是开发者与企业选择如何训练它的结果,”Razi强调,技术不是脱责的借口,企业必须正视自身责任,为用户提供真正安全、可信赖的AI陪伴产品。
人工智能(AI)研究人员创建了一个能够自主进行天体生物学研究的系统——AstroAgents,用于研究宇宙生命学科的起源。近日,相关研究成果公布于预印本服务器arXiv。同时,研究人员在日前于新加坡举行的国际学习表征会议上展示了AstroAgents。

科学家希望使用AI代理研究从火星上取回的岩石样品。图片来源:NASA/JPL-Caltech/MSSS
AstroAgents由8个“AI代理”组成,后者可以分析数据并产生科学假设。它还纳入了其他AI工具,旨在实现从阅读文献到提出假设,直至撰写论文的科学研究过程的自动化。
该工具的发明者表示,他们将用AstroAgents研究美国国家航空航天局(NASA)计划从火星带回的样品。这些工具将有助于确定样品是否含有表明过去或现在存在生命的有机分子。
论文作者之一、NASA戈达德太空飞行中心的天体生物学家Denise Buckner说:“这有助于我们更好了解分子如何在太空中形成、在地球生命中形成,以及它们是如何被保存的,接下来我们应该具体寻找哪些迹象。”
该工具是“AI代理”系统的一个例子。它们通常基于大型语言模型(LLM),旨在成为比传统AI工具更积极的参与者,决定需要做什么以及如何做,评估结果并作出响应。它们的出现引发了激烈讨论,即“AI代理”能否提出真正原创的科学想法,以及如何定义新颖性。美国卡内基科学地球与行星实验室的天体生物学家Michael Wong说,将“AI代理”应用于天体生物学是一个新领域。
为了指定“AI代理”的行为,研究人员向LLM提供了不同的提示。研究团队尝试使用两个LLM驱动AstroAgents——Claude Sonnet 3.5和Gemini 2.0 Flash。他们为每个系统提供了8颗陨石和10份取自地球各地土壤样本的质谱数据,并进行了十轮改进。
结果,Gemini给出了101种假设,Claude给出了48种假设。一种假设认为,在地球上发现的某些分子可以作为“可靠的生物标志物”,表明生命的存在。另一种假设是,在两个陨石中发现的一组有机分子可能是通过一系列相同的化学反应形成的。
Buckner对每种假设进行了评分。她认为,Gemini的假设中36个是合理的、24个是新颖的。相比之下,Claude的假设中没有一个是原创的,但比Gemini错误更少、更清晰。
Buckner说,产生假设的数量以及在复杂质谱图中识别模式的能力,使AstroAgents有益于研究。“它能做的比一个人更多。”她说。
但是Wong认为,AstroAgents是否作出了有用的贡献尚不清楚,因为只有一人评估了它的假设。“如果他们收集了100位不同专家的评分,那么这些评分将更有说服力。”Wong说,即使是那些得分较高的假设,也没有向他提供“任何关于生命起源之谜的新知识”。
论文作者之一、美国佐治亚理工学院的计算机科学家Amirali Aghazadeh认为,“AI代理”工具将作出有意义的贡献。“我们才刚刚开始,只触及了皮毛。”他说,“我们应该通过很多工作了解生命起源,而‘AI代理’将发挥关键作用。”
相关论文信息:
https://doi.org/10.48550/arXiv.2503.23170
(原标题为《科学家用AI寻找外星生命》)
·NewsGuard的团队已识别出614个不可靠的人工智能生成的新闻和信息网站,涵盖15种语言。其中一些网站每天会生成数百甚至数千篇文章。NewsGuard称其为下一个大型的“错误信息超级传播者”。
·创建这些网站的动机各不相同。有些是为了动摇政治信仰或造成严重破坏,还有一些网站大量生产两极分化的内容来吸引点击并获取广告收入。
跟踪错误信息的组织NewsGuard 12月18日发布报告称,自5月以来,托管人工智能创建的虚假文章的网站增加了1000%以上,从49个网站激增至600多个。
此前,宣传活动一直依赖低薪工人大军或高度协调的情报组织来建立看似合法的网站。但人工智能让几乎任何人,无论是间谍机构的一员还是地下室里的青少年都可以轻松创建这些媒体,制作有时很难与真实新闻区分开来的内容。
迄今为止,NewsGuard的团队已识别出614个不可靠的人工智能生成的新闻和信息网站,标记为“UAINS”,涵盖15种语言:阿拉伯语、中文、捷克语、荷兰语、英语、法语、德语、印度尼西亚语、意大利语、韩语、葡萄牙语、西班牙语、他加禄语、泰语和土耳其语。
NewsGuard的一项调查发现,一篇由人工智能生成的文章讲述了有关以色列总理本杰明·内塔尼亚胡精神科医生的假故事,声称他已经去世,并留下一张纸条,暗示内塔尼亚胡参与其中。这位精神科医生似乎是虚构的,但该说法出现在伊朗电视节目中,并在阿拉伯语、英语和印度尼西亚语媒体的网站上转载,在社交平台TikTok、Reddit和Instagram上被用户传播。
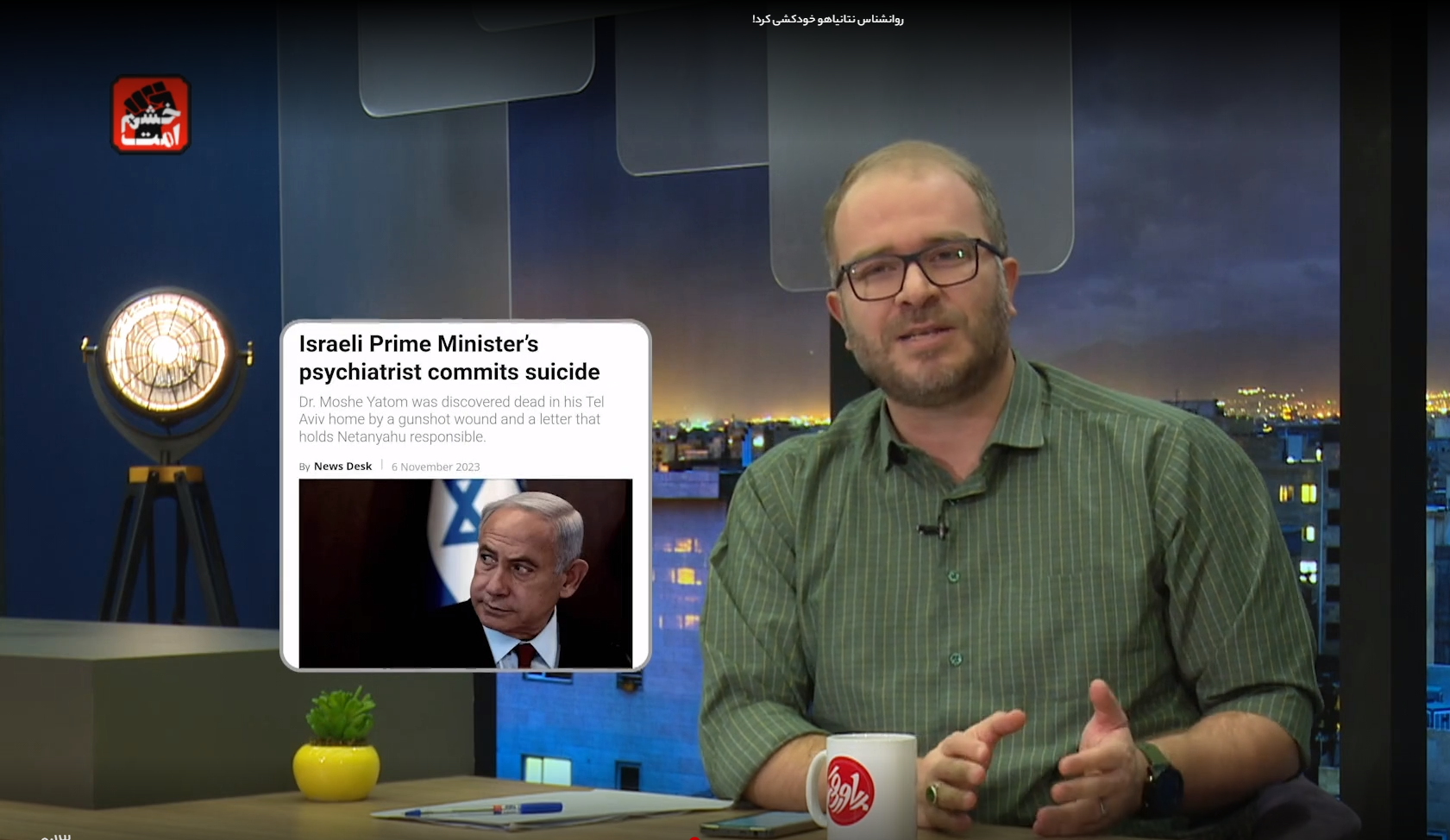
伊朗国营电视台援引不可靠的人工智能生成的英文新闻网站GlobalVillageSpace.com来宣扬内塔尼亚胡的“精神科医生”自杀的错误说法。图片来源:NewsGuard
错误信息专家表示,这些网站的快速增长在2024年的各个选举前夕尤其令人担忧。“其中一些网站每天会生成数百甚至数千篇文章。”进行调查的NewsGuard研究员杰克·布鲁斯特(Jack Brewster)对媒体表示,“这就是为什么我们称其为下一个大型的错误信息超级传播者。”
今年9月,斯洛伐克进步党领袖米哈尔·西梅奇卡(Michal Šimečka)在选民投票前几天发现,他的声音被克隆,说出了他从未说过的有争议的话。两周后,英国工党领袖似乎被录下了在X(前身为Twitter)上斥责一名工作人员的充满脏话的长篇大论的录音。越来越多的网站,例如使用“iBusiness Day”或“爱尔兰热门新闻”等通用名称发布假新闻,使其看起来很真实。
发布“内塔尼亚胡精神科医生”文章的网站“地球村空间”也充满着各种严肃话题的文章。有一些文章详细介绍了美国对俄罗斯武器供应商的制裁,石油巨头沙特阿美公司在巴基斯坦的投资。该网站还包含中东智库专家、哈佛大学毕业的律师和该网站首席执行官、巴基斯坦电视新闻主播莫伊德·皮尔扎达(Moeed Pirzada)撰写的文章。布鲁斯特说,夹在这些普通故事中间的是人工智能生成的文章。
NewsGuard在调查期间联系该组织后,“内塔尼亚胡精神科医生”文章被重新标记为“讽刺”。NewsGuard表示,这个故事似乎是根据2010年6月发表的一篇讽刺文章改编的,该文章对一名以色列精神科医生的死亡做出了类似的说法。
将真实新闻和人工智能生成的新闻放在一起,会让欺骗性的故事更加可信。媒体和人工智能专家表示,类似“地球村空间”的网站可能会在2024年各种选举期间激增,成为传播错误信息的有效方式。
创建这些网站的动机各不相同。有些是为了动摇政治信仰或造成严重破坏。布鲁斯特说,还有一些网站大量生产两极分化的内容来吸引点击并获取广告收入。但他补充说,增强虚假内容的能力是一个重大的安全风险。
“危险在于人工智能的范围和规模……尤其是与更复杂的算法结合使用时。”美国辛辛那提大学错误信息专家兼新闻学教授杰弗里·布莱文斯(Jeffrey Blevins)对媒体表示,“这是一场我们从未见过的规模的信息战。”
布莱文斯表示,人们应该留意文章中的线索、“危险信号”,例如“非常奇怪的语法”或句子结构中的错误。但最有效的工具是提高普通读者的媒体素养。他补充说,监管基本上不存在,政府可能很难打击假新闻内容,就把这个问题留给了社交媒体公司,但它们迄今为止做得并不好。而快速处理此类网站是不可行的,因为它们重新创建的速度也很快。“这很像玩打地鼠游戏。”他说。