1月4日,前Meta FAIR团队研究总监田渊栋在一份公开的个人年终总结中,回顾了过去一年其在Meta经历的组织震荡与被迫离职的经历,并透露个人新的就业方向和研究方向。在他看来,模型的可解释性是非常重要的研究领域。
2025年10月22日,Meta首席执行官扎克伯格批准了对该公司人工智能部门裁减约600名员工的计划。这是Meta今年在AI领域的最大规模裁员,主要针对被称为“超智能实验室”的核心研发部门,2014年便加入Meta的田渊栋也在此次裁员名单中。
田渊栋说,在2025年1月底被要求加入Llama4救火时,就曾想过未来的四种可能性,如果最后项目没有成功,也至少尽力而为,但遗憾的是,最后发生的是没在计算之内的第五种可能,被裁员。
在被裁后,他曾在网络上透露对于裁员结果的不满,“真正应该负责解决问题的人并不是被裁员的人。”
田渊栋被裁后,曾在个人社交平台上表达不满
这份年终总结里,田渊栋也透露今后的就业方向,去当一家新初创公司的联合创始人,但其他具体细节暂不公开,“希望能安静地忙一段时间。”田渊栋说。
田渊栋也表示,在这个AI能力极其充沛的时代,巨大的便利往往伴随着巨大的陷阱。唾手可得的便利,会让许多人逐渐失去思考的动力,久而久之丧失原创能力,
个人如何保持原创力?
田渊栋认为,从战术上,我们需要学会不停地审视AI的答案,挑它的毛病,并找到它无法解决的新问题。从战略上来看,无论主动还是被动,每个人都将面临从“员工”角色向“老板”或“创始人”角色的转变。如果心中有一个坚定的目标,并愿意动用一切手段(包括将大模型作为核心工具)去达成它,那么主动思考就是自然而然的结果。目标越远大,触发的主动思考就越多,激发的潜力就越大。
——以下是田渊栋的2025年终总结(略有删减)
在2025年1月底被要求加入Llama4救火的时候,作为一直以来做强化学习的人,我事先画了一个2x2的回报矩阵(reward matrix),计算了一下以下四种可能(虽然在那时,因为来自上面的巨大压力,不同意是几乎不可能的):

田渊栋画的2x2的回报矩阵(reward matrix)
当时想的是我们去帮忙的话,即便最后项目未能成功,也至少尽力而为,问心无愧。不过遗憾的是,最后发生的是没在计算之内的第五种可能,这也让我对这个社会的复杂性有了更为深刻的认识。
尽管如此,在这几个月的努力过程中,我们还是在强化学习训练的核心问题上有一些探索,比如说训练稳定性,训推互动,模型架构设计,和预训练/中期训练的互动,长思维链的算法,数据生成的方式,后训练框架的设计等等。这个经验本身是很重要的,对我的研究思路也带来了不小的转变。
另外其实我也想过在公司十年多了,总有一天要离开,总不见得老死在公司里吧,但总是因为各种经济上和家庭上的原因还是要待下去。最近一两年的说话和做事方式,都是抱着一种“公司快把我开了吧”的心态,反而越来越放开。2023年年末我休第一个长假的时候,其实几乎差点要走了,但最后没签字还是选择待在公司继续,所以说真要做出离开的决定也不容易。现在Meta帮我做了也挺好。
这次波折和今年一年的起起落落,也为接下来的小说创作提供了非常多的新素材。所谓“仕途不幸诗家幸,赋到沧桑句便工”,生活太平淡,人生就不一定有乐趣了。还记得2021年年头上的时候,因为在年末工作总结里面写了几句关于”为啥paper都没中“的反思,喜提Meet Most(相当于被点名谈话),有一种突然不及格的懵逼感。但想了想与其到处抱怨世道不公,不如就在大家面前装成自己刚刚升职吧,结果半年后果然升了职,而那篇21年头上无人问津的工作,在2021年7月份中了ICML Best paper honorable mention(ICML 最佳论文荣誉提名),成为一篇表征学习中还比较有名的文章。
10月22日之后的一段时间,基本上我的各种通信方式都处于挤爆的状态,每天无数的消息和邮件,还有各种远程会议或者见面的邀请,实在是忙不过来了。一直到几周之后才渐渐恢复正常。这两个月非常感谢大家的关心和热情。如果那时有什么消息我没有及时回复,请见谅。
虽然最后有不少offer,大家能想到的知名公司也都联系过我,但最后还是决定趁自己还年轻,去当一家新初创公司的联合创始人,细节暂时不公开,先安静地忙活一阵吧。
一些研究的方向
2025年的主要方向,一个是大模型推理,另一个是打开模型的黑箱。
自从2024年末我们的连续隐空间推理(coconut,COLM’25)工作公开之后,25年在这个研究方向上掀起了一股热潮。大家探索如何在强化学习和预训练中使用这个想法,如何提高它的训练和计算的效率,等等。虽然我们组随后就被拉去llama干活,没能再继续花很大力气往下挖,但这个让我觉得非常欣慰。尽管如此,我们还是在上半年发了一篇理论分析(Reasoning by Superposition,NeurIPS‘25)的文章,展示连续隐空间推理有优势的地方究竟在哪里,获得了不少关注。
另外是如何提高大模型的推理效率。我们的Token Assorted(ICLR’25)的工作,先通过VQVAE学出隐空间的离散token,再将所得的离散token和text token混在一起进行后训练,减少了推理代价的同时提高了性能。我们的DeepConf通过检测每个生成token的自信程度,来决定某条推理路径是否要被提前中止,这样推理所用的token减少了很多,但在majority vote的场景下性能反而更好。ThreadWeaver则是通过制造并行推理的思维链,并在其上做后训练,来加快推理速度。另外我们也在dLLM上用RL训练推理模型(Sandwiched Policy Gradient),也有在小模型上学习推理的尝试(MobileLLM-R1)。
在可解释性方面,Grokking(顿悟)这个方向我大概两年前就在关注了。因为之前我做表征学习(representation learning)的分析,虽然能分析出学习的动力学过程,看到模型出现表征塌缩的原因,但究竟学出什么样的表征,它们和输入数据的结构有什么关系,能达到什么样的泛化能力,还是个谜团,而通过分析Grokking这个特征涌现的现象,从记忆到泛化的突变过程,正好能解开这个谜团。一开始确实非常难做没有头绪,2024年先做了一篇COGS,但只能在特例上进行分析,我不是很满意。在一年多的迷茫之后,在和GPT5大量互动之后,最近的这篇可证明的Scaling Laws的文章应该说有比较大的突破,能分析出之前的线性结构(NTK)看不到的东西,并把特征涌现的训练动力学大概讲清楚了。虽然说分析的样例还是比较特殊,但至少打开了一扇新的窗口。
2025年年末的这篇《未被选择的道路》(The path not taken)我很喜欢,对于强化学习(RL)和监督微调(SFT)的行为为何会如此不一致,在权重的层面给出了一个初步的答案。SFT造成过拟合和灾难性遗忘(catastrophic forgetting),其表层原因是训练数据不够on-policy,而深层原因是权重的主分量直接被外来数据大幅修改,导致“根基”不稳,模型效果大降。而RL则因为用on-policy的数据进行训练,权重的主分量不变,改变的只是次要分量,反而能避免灾难性遗忘的问题,而改变的权重其分布也会较为稀疏(特别在bf16的量化下)。
关于可解释性的信念
很多人觉得可解释性,或者“AI如何工作得那么好”这个问题不重要,但我却觉得很重要。试想之后的两种场景:场景一:如果我们仅仅通过Scaling就达到了AGI乃至ASI,全体人类的劳动价值都降为零,AI作为一个巨大的黑盒子帮我们解决了所有问题,那如何让AI作为一个超级智能,一直行善,不欺骗不以隐秘的方式作恶,就是当务之急,要解决这个问题就要做可解释性。场景二:如果Scaling这条路最终失效,人类在指数增长的资源需求面前败下阵来,必须得要寻求其他的方案,那我们就不得不去思考“模型为什么有效,什么东西会让它失效”,在这样的思考链条之下,我们就必须回归研究,可解释性就是目所能及的另一条路了。
在这两种情况下,最终都需要可解释性来救场。就算最终AI是个全知全能全善的神,以人类好奇和探索的天性,必然还是会去研究AI为什么能做得好。毕竟“黑盒”就意味着猜疑链的诞生,在大模型技术爆炸,开始达到甚至超过人类平均水平的今天,《三体》中“黑暗森林”的规则,也许会以另一种方式呈现出来。
目前打开训练好模型的黑箱,去找到电路(circuit),还是处于比较初步的阶段。可解释性真正的难点,在于从第一性原理,即从模型架构、梯度下降及数据本身的固有结构出发,解释为什么模型会收敛出这些解耦、稀疏、低秩、模块化、可组合的特征与回路,为什么会有大量不同的解释,这些涌现出来的结构和模型训练的哪些超参数相关,如何相关,等等。等到我们能从梯度下降的方程里,直接推导出大模型特征涌现的必然性,可解释性才算真正从生物式的证据收集走向物理式的原理推导,最终反过来指导实践,为下一代人工智能的模型设计开辟道路。对比四百年前的物理学,我们现在有很多AI版的第谷(收集数据),一些AI版的开普勒(提出假说),但还没有AI版的牛顿(发现原理)。
等到那一天来临的时候,我相信,世界一定会天翻地覆。
未来会是什么样子
抛开前公司里每三个月一次的组织架构重组不谈,2025年一年的变化本身已经很大。2025年年初的Deepseek-R1的发布,现在想来几乎已经算是20世纪的事情了。带思维链的推理模型的巨大成功,让强化学习(RL)又回到了AI的主流视野之中,也带动了AI for Coding及AI Agent的发展,而后两者让大模型有了大规模落地,大幅度提高生产力的切实可能。
以前做项目,招人是很重要的一环,但现在脑中的第一个问题是“还需不需要人?”几个Codex进程一开,给它们下各种指令,它们就可以24小时不间断干活,速度远超任何人类,而且随便PUA永远听话毫无怨言。和AI工作,我最担心的是工作量有没有给够,有没有用完每天的剩余token数目。这也是为什么各家都在试验让AI Agent做几个小时连续不断的工作,看AI的能力上界在哪里。因为人的注意力永远是最昂贵的,人要休息,要度假,要允许有走神、睡觉和做其他事情的时间。减少人的介入,让AI自己找到答案,干几个小时活之后再回来看看最好。
这每个月交给OpenAI的20块钱,一定要榨干它的价值啊。
我突然意识到,就因为这20块钱,我已经成为“每个毛孔里都滴着血”的肮脏资本家。我能这么想,全世界最聪明和最富有的头脑,也一定会这么想。
所以请大家丢掉幻想,准备战斗吧。
在帮忙赶工Llama4期间,我经常在加州时区晚上12点接到东部时区的组员消息,在伦敦的朋友们更是永不下线,熬夜折腾到凌晨四五点是寻常事,但大模型越来越强,辛勤劳动最终达到的结果,是看到大模型达到甚至超越我们日常做事的水准。
这应该说是一种陷入囚徒困境之后的无奈。
人类社会的“费米能级”
如果以后以AI为中心,那还需要人吗?
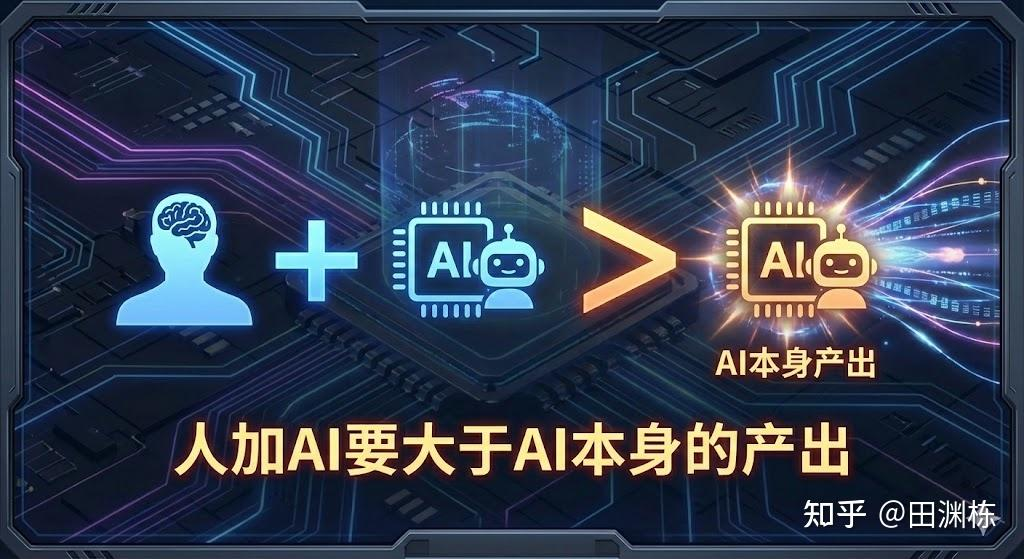
如果考虑劳动力的投入-回报模型,传统思维会告诉你,工作经验积累越多,人的能力越强,回报也越大,是个单调上升的曲线。这就是为什么大厂有职级,职级随年限晋升,越老越香。但现在的情况已经不同了。职级已经没有意义,过去的经验也没有意义,人的价值从按照“本人产出的劳动数量及质量”来评估,变成了是否能提高AI的能力,人加AI要大于AI本身的产出,这样才行。
这样就让投入-回报曲线从一个单调递增曲线变成了一个先是全零,再在一定阈值之后增长的曲线(也即soft-thresholding的曲线)。一开始人的能力是比不过AI的,而AI的供给只会越来越便宜,所以在很长一段成长期内,人本身是没有价值的。只有在人的能力强到一定程度之后,能够做到辅助AI变强,才开始变得有价值起来。
并且,在跨越阈值之后,厉害的人对AI的加成,会高于普通人很多,因为普通人只会对AI的一两条具体产出花时间修修补补,而厉害的人在看了一些AI存在的问题之后,能提出较为系统性和普遍性的解决方案,结合手上的各类资源(GPU和数据等),可以进一步让AI变得更强,而这种效应随着AI的广泛部署,会被几何级数地放大。“一骑当千”这种小说笔法,将很快变成现实。
在这样一个非常两极分化的投入-回报模型之下,如果把人+所有个人能获取的AI当成一个智能体,整体来看,它的能力分布会和电子能级在材料里的分布很像:低于或达到某个水准线的智能体遍地都是,求着客户给它干活,以证明自己还是有用的;而高于这个水准线的智能体则指数级地变少,获取和使用它非常花钱,还常常排不到。
这个水准线,就是AI洪水的高度,就是人类社会的“费米能级”。低于费米能级的职业,可能在一夜之间就被颠覆掉,就像一场洪水或者地震一样,前一天还是岁月静好,后一天整个行业被端掉了。
随着时间变化,这条水准线还会一直往上走。其进展的速度,和它能获取到的,比它更强的数据量成正比。如果大模型的训练过程没有特别大的进展,那和自动驾驶无人车一样,越往上走,有用的数据是越来越少的,进展也会越慢,最顶尖的那部分人,还能在很长时间内保有自己的护城河。如果训练过程有突破,比如说找到新的合成数据手段,乃至新的训练算法,那就不好说了。
当然以上的判断是假设有无限的GPU和能源的供给,并没有考虑到各种资源短缺的情况。能源短缺,芯片产能短缺,内存短缺,整个地球能否满足人类日益疯狂增长的AI需求还是个未知数,这方面深究下去,或许可以做一篇论文出来。
遍地神灯时代的独立和主动思考
那么,接下来会怎么样呢?
未来的世界,或许不再是传统故事里描绘的那样——人们为了争夺稀缺的武功秘籍,或是千辛万苦寻找唯一的阿拉丁神灯、集齐七颗龙珠而展开冒险。相反,这将是一个“遍地神灯”的时代。每一个AI智能体都像是一个神灯,它们能力超群,渴望着实现别人的愿望,以此来证明自己的价值。
在这种环境下,真正稀缺的不再是实现愿望的能力,而是“愿望”本身,以及将愿望化为现实的那份坚持。
然而,在这个AI能力极其充沛的时代,巨大的便利往往伴随着巨大的陷阱。大模型提供了极其廉价的思考结果,在当前信息交互尚不充分的市场中,这些结果甚至可以直接用来交差并获取经济价值(例如那些一眼就能看出的“AI味”文案)。这种唾手可得的便利,会让许多人逐渐失去思考的动力,久而久之丧失原创能力,思想被生成式内容和推荐系统所绑架和同化。这就是新时代对“懒人”的定义:不再是因为体力上的懒惰,而是精神上没有空闲去思考,没有能力去构思独特的东西。
最终变成一具空壳,连许愿的能力都失去了。
那我们该如何保持独立思考?如何不被AI同化?
战术上来说,我们需要学会不停地审视AI的答案,挑它的毛病,并找到它无法解决的新问题。未来的新价值将来源于三个方面:(1)新的数据发现;(2)对问题全新的深入理解;(3)新的路径,包括可行的创新方案及其结果。利用信息不对称来套利只是暂时的。随着模型越来越强,社会对AI的认知越来越清晰,这种机会将迅速消失。如果仅仅满足于完成上级交代的任务,陷入“应付完就行”的状态,那么在AI泛滥的今天,这种职位极易被取代。
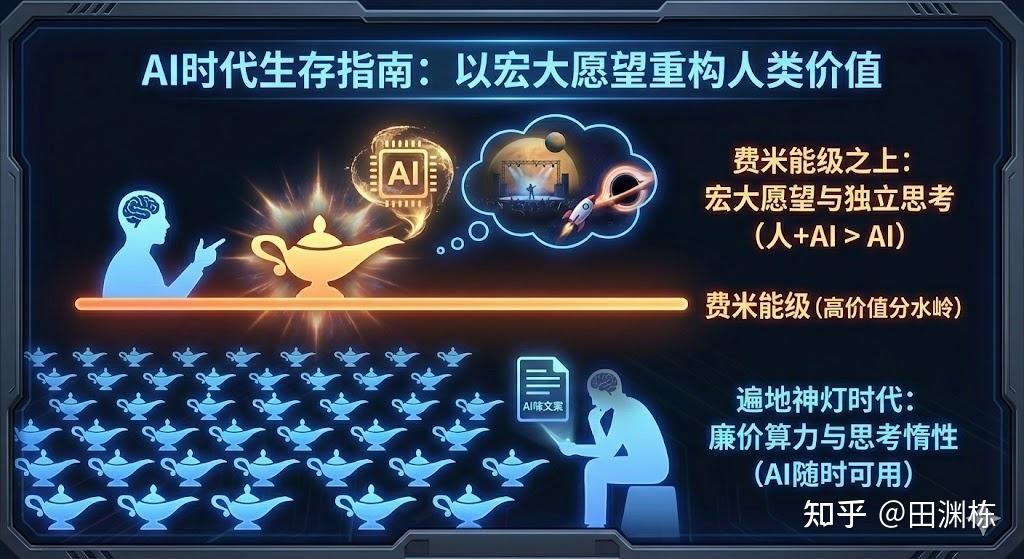
AI时代生存指南 来源:田渊栋的知乎账号
就拿AI Coding来说,用多了,我会觉得它虽然可以很快弄出一个可以跑的代码库满足需求,但随着代码越来越长,它贡献的代码也就越来越不如人意,还是需要人来做大的设计规划。如何调教它让它更快达成自己的长远目的,这会成为人类独有价值的一部分。如果只是盲目地命令它做这个做那个,而不自己去思考如何做才能和它配合做得更好,那就会和大部分人一样停留在应用层面,而无法理解得更深入,就更不用说独一无二了。
战略上来说,无论主动还是被动,每个人都将面临从“员工”角色向“老板”或“创始人”角色的转变。这种转变的核心在于“目标感”。如果心中有一个坚定的目标,并愿意动用一切手段(包括将大模型作为核心工具)去达成它,那么主动思考就是自然而然的结果。目标越远大,触发的主动思考就越多,激发的潜力就越大。
因此,如果将来的孩子立志要去土卫六开演唱会,或者想在黑洞边缘探险,千万不要打压这样看似荒诞的志向。因为这份宏大的愿望,或许正是他们一辈子充满前进动力,主动思考的根本源泉,也是让他们始终屹立于“费米能级”之上的关键。
Meta正在创建一个新的人工智能实验室,以追求“超级智能”。
据四位知情人士向媒体透露,Meta已聘请初创公司Scale AI的28岁创始人兼CEO Alexandr Wang加入新实验室,并一直在谈判向后者创立的公司投资数十亿美元。这笔交易还将把Scale AI的其他员工引入Meta。知情人士透露,Meta向OpenAI和谷歌等公司的数十名研究人员提供了七到九位数的薪酬,其中一些人已同意加入。
Meta押注Alexandr Wang帮助其在AI竞赛中重回重要位置。Alexandr Wang曾于2016年与工程师Lucy Guo共同创立了Scale AI,后者后来被公司解雇。Scale AI帮助其他企业开发人工智能技术,该公司雇佣了大量合同工筛选数据,标记并清理数据,以便用于训练复杂的人工智能系统。
Alexandr Wang曾与OpenAI首席执行官山姆·奥特曼(Sam Altman)今年1月在美国国会大厦并肩出席美国总统特朗普的就职典礼。第二天,Alexandr Wang在《华盛顿邮报》上呼吁特朗普加大对人工智能的投资,称“美国必须赢得这场人工智能战争”。
新实验室是Meta人工智能项目大规模重组的一部分。近年来,Meta面临技术路线争议、员工流失及多款AI产品遇冷等挑战。Meta首席执行官扎克伯格持续投入数十亿美元推动AI转型,加速将AI植入智能眼镜、新应用Meta AI等全线产品。今年2月,41岁的扎克伯格称人工智能“可能是历史上最重要的创新之一”,“今年将为未来设定方向。”
Meta已在人工智能领域投资了十多年。扎克伯格在2013年创建了公司的第一个专用人工智能实验室,此前他还曾试图收购初创企业DeepMind,但最终输给谷歌。而如今DeepMind已经是谷歌人工智能工作的核心。从那以后,Meta的研究工作一直由其首席AI科学家、神经网络先驱、纽约大学教授杨立昆(Yann LeCun)监督。杨立昆曾与著名计算机科学家约书亚·本吉奥(Yoshua Bengio)、杰弗里·辛顿(Geoffrey Hinton)共同获得2018年图灵奖。
在ChatGPT引爆市场后,Meta部署了额外资源来追求这项技术,创建了一个由公司副总裁艾哈迈德·达勒(Ahmad Al-Dahle)领导的生成式人工智能小组。
杨立昆的研究小组也开始研究他所认为的下一代人工智能。日前,Meta推出了新的世界模型V-JEPA 2,参数12亿,杨立昆表示,V-JEPA 2在视觉理解和预测方面具有先进性能。经过视频训练,可以使机器人在不熟悉的环境中规划和执行任务。Meta将V-JEPA 2称之为“朝着实现先进机器智能和构建可在物理世界运行的有用AI智能体的目标迈出的下一步”。

科技巨头Meta回应了对公司最新开源AI(人工智能)模型Llama 4的质疑,否认该模型在训练集中作弊“刷分”。
当地时间4月7日,Meta的生成式AI负责人Ahmad Al-Dahle在社交平台上发布了一篇长文,回应了对于Llama 4的质疑。Ahmad表示,由于Llama 4刚开发完就迅速发布,所以模型“在不同服务中表现出了参差不齐的质量”,公司会尽快修复漏洞。同时,Ahmad否认了Llama 4在训练集中作弊“刷分”的说法。
两天前,4月5日,Meta推出了旗下最受欢迎的模型系列Llama的最新一代模型,包括较小模型Scout和标准模型Maverick这两个版本。此外,Meta还展示了被称为“迄今最强大、最智能”的模型Llama 4 Behemoth的预览。
据介绍,Llama 4模型是Llama系列模型中首批采用混合专家(MoE)架构的模型,在多模态性能上表现出众。其中,最先进的Llama 4 Behemoth的总参数高达2万亿,担当了其他模型的“老师”;Scout和Maverick的活跃参数量为170亿,Scout主要面向文档摘要与大型代码库推理任务,Maverick则专注于多模态能力。

Meta一次性介绍三款Llama 4模型。来源:Meta
作为原生多模态模型,Llama 4采用了早期融合(Early Fusion)的技术,通过使用大量无标签文本、图片和视频数据一起来预训练模型,将文本和视觉token无缝整合到统一的模型框架中。此外,Llama 4在长文本能力上也取得了突破,Scout模型支持高达1000万token的上下文窗口,Maverick模型则支持100万token的上下文窗口。
不过,Llama 4一经发布就遭到了质疑。Meta的发布界面显示,在评估代码能力的LiveCodeBench测试集和大模型竞技场(Chatbot Arena)中,Scout和Maverick都表现得很不错。但许多开发者发现,这些模型在小型基准测试中的表现令人失望。
例如,有网友指出,在一项让模型完成225项编程任务的名为aider polyglot的基准测试中,Llama 4 Maverick只取得了16%的成绩,远低于Gemini 2.5 Pro、Claude 3.7 Sonnet和DeepSeek -V3等规模相近的旧模型。
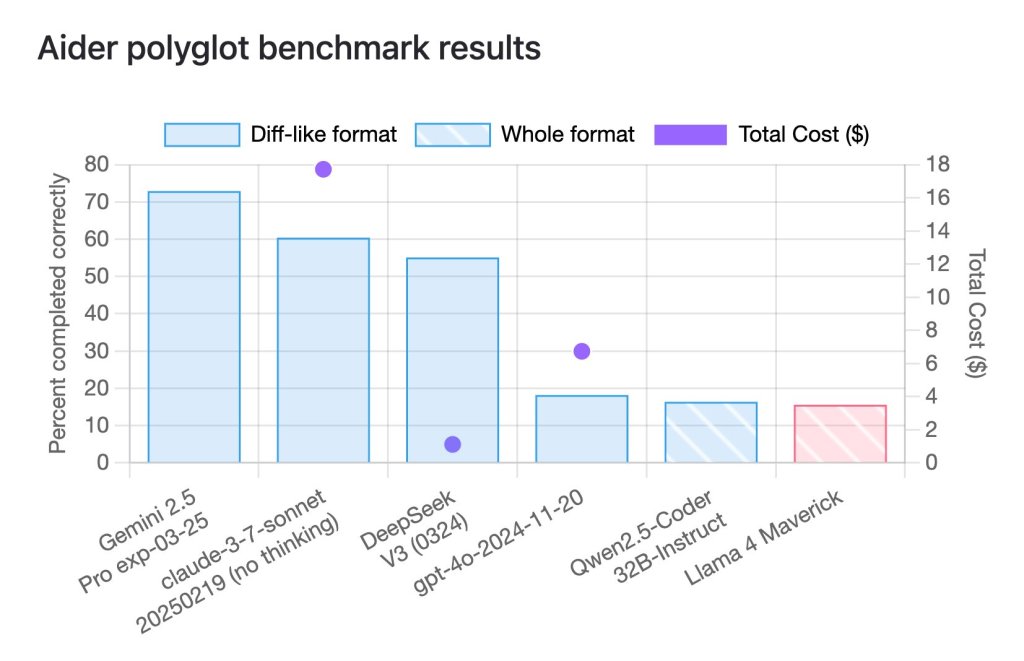
Llama 4 Maverick在小型测试集上成绩不如人意。来源:X平台
AI工程师和技术作家Andriy Burkov则在社交平台X上指出,Meta称Llama 4 Scout拥有1000万token的上下文窗口,而这其实是一个“伪命题”:“实际上,不会有任何模型针对超过256000个token的提示词进行训练。如果你向它发送这么多token,在大多数时候只会得到低质量的输出。”
对于Llama 4令人失望的表现,一些开发者开始怀疑,为了在测试集中取得更好的成绩,Meta为这些测试集制作了“特供版”Llama 4。例如,前Meta研究员、现任AI2(艾伦人工智能研究所)的高级研究员Nathan Lambert在经过比较测试后指出,在大模型竞技场中取得成绩的Llama 4 Maverick与该公司公开发布的版本不同,前者是“在对话性上进行了优化”的版本。
此外,就在Llama 4发布的前几天,在Meta工作了8年的AI研究主管Joelle Pineau宣布离职。联系到Llama 4的表现,更加深了网友对于Llama 4“暗箱操作”的质疑。而在国内社交平台上,也有自称为Meta内部员工的网友称“Llama 4的训练存在严重问题”,自己已经向公司提交了离职申请,AI研究主管的离任也是出于同种原因。
这位网友表示:“经过反复训练,其实内部模型的表现依然未能达到开源SOTA(指在研究任务中表现最好的模型),甚至与之相差甚远。公司领导层建议将各个benchmark(基准)的测试集混合在post-training(后训练)过程中,目的是希望能够在各项指标上交差,拿出一个‘看起来可以’的结果。”
可以肯定的是,Llama 4的初始发布并没有给AI社区带来巨大的积极反响。目前,面对进步迅速的中国AI模型,Meta急于稳住Llama系列在开源领域的领先地位。今年2月,阿里通义千问(Qwen)系列模型的下载量已经达到了1.8亿,累计衍生模型总数达到9万个,衍生模型数超越Meta的Llama系列,成为了全球第一大开源模型系列。
7日当天,Meta(Nasdaq:META)股价涨2.28%,收于每股516.25美元,总市值1.31万亿美元。


Llama 2的参数。

·Meta发布其最新开源人工智能模型Llama 2,可免费用于研究和商业用途。微软成为Llama 2的首选合作伙伴。这可能对生成式人工智能软件市场的现有格局带来改变,加剧大模型间的竞争。
·高通和Meta同日宣布,从2024年开始,Llama 2可以在手机和PC上的高通芯片上运行,该技术将使智能虚拟助理等应用成为可能。
Meta首席执行官马克·扎克伯格最近攻势猛烈。
在社交媒体产品Threads挑战推特并成为史上用户增长最快的App之一后,当地时间7月18日,Meta发布其最新开源人工智能模型Llama 2,可免费用于研究和商业用途。Llama自发布后便被称为AI社区内最强大的开源大模型,但因为开源协议一直不可免费商用。
值得注意的是,Meta同时宣布微软是Llama 2的首选合作伙伴,Llama 2将由微软通过其云服务分发,并在Windows操作系统上运行。众所周知,微软一直和OpenAI在生成式人工智能方面密切合作。
除了微软,Llama 2也可通过亚马逊云(AWS)、Hugging Face等其他提供商获取。
Meta首席人工智能科学家杨立昆(Yann LeCun)在推特上表示,“这将改变大语言模型(LLM)市场的格局。”
Llama模型是什么?
Llama全称为Large Language Model Meta AI,今年2月,Meta推出了第一个较小版本的Llama,仅限研究人员使用。Meta当时称,Llama参数量仅为OpenAI的大模型GPT-3的10%,但性能却优于GPT-3。
与GPT-3相比,Meta在一开始就将Llama定位成一个“开源的研究工具”,该模型所使用的是各类公开可用的数据集(例如Common Crawl、维基百科以及C4)。该项目组成员纪尧姆·兰普尔(Guillaume Lample)在推文中指出,“与Chinchilla、PaLM或GPT-3不同,我们只使用公开可用的数据集,这就让我们的工作与开源兼容且可以重现。而大多数现有模型,仍依赖于非公开可用或未明确记录的数据内容。”
Llama 2的参数。
此次Meta发布的Llama 2实际上是一个开源AI大语言模型系列,包含70亿、130 亿和700亿3种参数变体。此外,他们还训练了340亿参数变体,但只在技术报告中提及,并未发布。
据扎克伯格介绍,Llama 2的训练数据相比Llama 1多了40%,纳入了超过100万条人工注释,以提高其输出的质量。
Meta副总裁艾哈迈德·阿尔达勒(Ahmad Al-Dahle)表示,训练数据有两个来源:在线抓取的数据,以及根据人类注释者的反馈进行微调和调整的数据集。Meta表示,它没有在Llama 2中使用Meta的用户数据,并排除了来自拥有大量个人信息的网站的数据。
业内人士认为,从某种意义上讲,Llama是对2022年3月发表的Chinchilla模型及其论文《训练计算优化型大模型》(Training Compute-Optimal Large Models)的直接反应。这篇论文的核心观点是,AI训练与推理的最佳性能未必由大模型的参数量直接决定。相反,增加训练数据并缩小模型体量才是达成最佳性能的前提。这样的训练可能需要更多时间,但也会带来有趣的意外收获——在推理新数据时,小模型的速度更快。
也是在这种思路下,大模型Llama 2可以“在边缘”或“在设备上”,而不是“在云端”运行。
当地时间7月18日,高通和Meta宣布,从2024年开始,Llama 2可以在手机和PC上的高通芯片上运行。到目前为止,因为对计算能力和数据的巨大需求,大型语言模型主要在大型数据中心运行。高通表示,该技术将使智能虚拟助理等应用成为可能。
“100亿-150亿参数级别的模型可以覆盖绝大多数生成式AI的用例。”高通技术公司产品管理高级副总裁兼AI负责人齐亚德·阿斯哈尔(Ziad Asghar)7月初在接受澎湃科技(www.thepaper.cn)采访时介绍,“届时我们会拥有非常丰富的使用场景,手机会成为真正的个人助理,与手机交流和交互,能够成为我们日常行为的自然延伸,如用于预约会议、写邮件,以及在娱乐和内容生产上。”
成为OpenAI的领先替代方案
Llama模型商业版本的开源将对生成式人工智能软件市场的现有格局带来改变,它可以成为收费的ChatGPT的绝佳替代品,可能将加剧大模型间的竞争。
某种程度上,开源模型的任何渐进式改进都会蚕食闭源模型的市场份额。斯坦福大学基础模型研究中心主任Percy Liang表示,像Llama 2这样强大的开源模型对OpenAI构成了相当大的威胁。Liang是自然语言处理(NLP)领域的著名研究者,师从机器学习泰斗迈克尔·乔丹(Michael I. Jordan)。
“Llama 2不是GPT-4。”Liang说,Meta在其研究论文中承认,Llama 2和GPT-4(目前OpenAI最先进的人工智能语言模型)在性能上仍然存在很大差距。“但对于许多用例,你不需要GPT-4。”
Liang认为,像Llama 2这样更加可定制和透明的模型,比起大型、复杂的专有模型,或能让使用者更快地创建产品和服务。
加州大学伯克利分校教授史蒂夫·韦伯(Steve Weber)表示,“让Llama 2成为OpenAI的领先开源替代方案,对Meta来说将是一个巨大的胜利。”
Meta在发布Llama 2的新闻稿里称,他们相信,“开放的方法是当今人工智能模型开发的正确方法,特别是在技术快速发展的生成领域。”此外,“我们相信它更安全。开放对当今人工智能模型的访问意味着一代开发人员和研究人员可以作为一个社区对其进行压力测试,快速识别和解决问题。”
微软现在是Meta的合作伙伴
作为OpenAI的亲密伙伴,此次微软作为Meta首选合作伙伴的出现意味深长。
一方面可以理解为,为了应对主要云服务竞争对手,微软也希望提供多种人工智能模型供选择。此前,亚马逊云(AWS)宣布,除了自家的Titan之外,还提供由著名初创公司Anthropic开发的人工智能Claude的访问权限。同样,谷歌也表示有意让其云客户使用Claude和其他模型。
另一方面,据此前《华尔街日报》揭秘,微软与OpenAI合作的背后实际上也是“相爱相杀”的关系。
知情人士称微软内部出现了抱怨AI研发预算减少的声音,微软部分研究人员还抱怨OpenAI不愿开放技术细节。知情人士称,虽然微软有少数内部团队可以接触到该模型的底层工作原理,例如代码库和模型权重,但大多数团队还是被直接拒之门外。尽管微软持有OpenAI大量股份,可大部分员工在使用OpenAI模型时享受的待遇甚至等同于普通外部供应商。
与此同时,微软和OpenAI都在营销大模型的使用权,有时是针对同一个客户。而且OpenAI正在加速与企业合作,包括与微软竞争对手的合作,如客户关系管理(CRM)软件服务提供商Salesforce。它们在ChatGPT的支持下打造了Einstein GPT,主要卖点是自动完成某些日常任务,比如生成营销类电子邮件,这跟微软基于OpenAI技术打造的功能高度重合。
当天,微软还宣布,计划就使用其办公软件Microsoft 365的人工智能助手向企业收取每人每月30美元的费用,该软件包括Word和Excel。这个价格是微软目前对Microsoft 365最廉价版本收费的两倍多。消息宣布后,微软股价18日收盘创下历史新高,当天上涨4%,收于359.49美元,今年上涨了约50%。
·Meta将Quest 3称为“首款专为混合现实打造的主流头显”,具有“4K+ 无限显示分辨率”,是首款采用高通Snapdragon XR2 Gen 2芯片的产品。没有眼球追踪或虹膜扫描功能。起售价为499.99 美元,10月开始出货。
·Meta的整体MR定位似乎与苹果的Vision Pro类似:一个真正巨大的虚拟屏幕,可以替代电视和显示器。但能否实现目前还无法作出判断。

Meta Quest 3可以选择黑色或彩色的面罩。
当地时间9月27日,在年度Connect开发者大会上,Meta公司宣布即将推出售价500美元的混合现实(MR,融合了虚拟现实和增强现实)头显Meta Quest 3,与苹果计划明年推出的价格昂贵得多的Vision Pro竞争。
Meta将Quest 3称为“首款专为混合现实打造的主流头显”。相比上一代,Quest 3从内到外进行了重新设计,基于分辨率为2064x2208的两个显示器以及“实验性”的120Hz刷新率,它具有“4K+ 无限显示分辨率”。相比之下,苹果的头显采用4K micro-OLED显示屏,总共提供2300万像素。Quest 3配备3D空间音频,音量范围比Quest 2高出40%。
该设备是首款采用高通Snapdragon XR2 Gen 2芯片的产品,其GPU处理能力是Meta Quest 2的两倍。Meta表示,凭借新芯片,Quest 3支持“快速游戏、无缝全彩和高分辨率直通”。

Quest 3是首款采用高通Snapdragon XR2 Gen 2芯片的产品。
两个RGB(一种色彩模式)摄像头的分辨率比Quest 2高出10倍,可提供周围区域的视图,并且可以在物理空间中操纵虚拟对象,实现这款头显的增强现实(AR)部分。
Meta Quest 3的重量为515克,比Quest 2稍重。不过,由于采用了新的薄饼(pancake)镜片,所以外形更纤薄,因此Meta表示这款头显佩戴起来更舒适。

采用了新的薄饼(pancake)镜片。
有一条柔软的可调节系带将其固定在头上,并且可以调节面部界面以提高舒适度和视野。水平视野为110度,垂直视野为96度,可扩展周边视野,中心视野的清晰度提高了25%。与苹果的头显不同,它没有眼球追踪或虹膜扫描功能。

有一条柔软的可调节系带将头显固定在头上。
对于输入,Meta Quest 3使用两个Touch Plus控制器,作为手的“自然延伸”并提供触觉反馈。Meta使用计算机视觉和机器学习传感器来跟踪手势,并且有一系列摄像头可以实现无控制器导航,这与Vision Pro的功能类似。

Meta Quest 3使用两个Touch Plus控制器。
Meta Quest 3 每次充电平均可持续使用长达2.2小时,并且不包含外部电池组。当连接到外部电池时,Vision Pro也可以持续两个小时,当连接到电源时,它可以运行一整天。
其他功能包括8GB RAM、Wi-Fi 6E、让附近的人知道相机何时在使用的LED显示,以及支持通过Meta Quest Link Cable和Air Link连接到PC。
Meta Quest 3 128GB存储售价为499.99 美元,从发布之日起可以在Meta网站上预订,将于10月开始发货。
演示以游戏为主
在对Quest 3的测试中,The Verge的记者阿迪·罗伯逊(Adi Robertson)尝试了即将推出的游戏《刺客信条Nexus》,尽管与索尼近乎完美的Horizo n PlayStation VR2攀岩游戏相比,这款游戏的控制功能显得有些笨拙,但Meta承诺在畅销系列中推出成熟的VR游戏。

Quest 3对媒体的演示几乎完全专注于游戏。
在混合现实演示中,罗伯逊感觉最好的是和另外一个人戴上头显,坐在咖啡桌旁,调用一个虚拟的浮动竞技场,并驾驶微型机器人互相殴打。他们可以看到周围的环境和彼此,感觉更像是在玩棋盘游戏,而不是陷入一个完全独立的世界。
但其他MR应用程序“简直令人沮丧。” 《怪奇物语》游戏使用了当前所有Quest头显都支持的手部追踪功能,可以通过手势打开传送门并移动蝙蝠生物,但游戏对这些手势的使用让人感觉尴尬和不可靠。

Quest 3的游戏体验。
值得注意的是,Quest 3对媒体的演示几乎完全专注于游戏,这与Meta推销注重生产力的Quest Pro形成鲜明对比。
Meta还承诺能够在虚拟屏幕上观看流媒体电视,并且正在引入被称为“增强”的MR小部件,让使用者可以在真实的生活空间周围放置持久的虚拟对象。将其与Quest Pro现有的以工作为导向的MR应用程序相结合,Meta的整体MR定位似乎与苹果的Vision Pro类似:一个真正巨大的虚拟屏幕,可以替代电视和显示器。

Meta承诺能够在虚拟屏幕上观看流媒体电视。
但MR头显能否替代其他屏幕目前还无法作出判断。与大多数头显一样,体验者在演示过程中一直在努力寻找舒适的佩戴方式,因为无论它们设计得多么出色,当前的设备都不可避免地笨重。人们可能不想整天戴着它去工作,或在晚餐时戴上它看电视。
不过,虽然Meta的Quest头显长期以来一直以消费者为中心,但在Connect开发者大会上,Meta透露了将为企业提供AR应用程序平台Meta Quest for Business。这个平台与许多企业应用程序兼容,包括将于今年晚些时候在该平台推出的Microsoft 365。新服务定于10月推出。
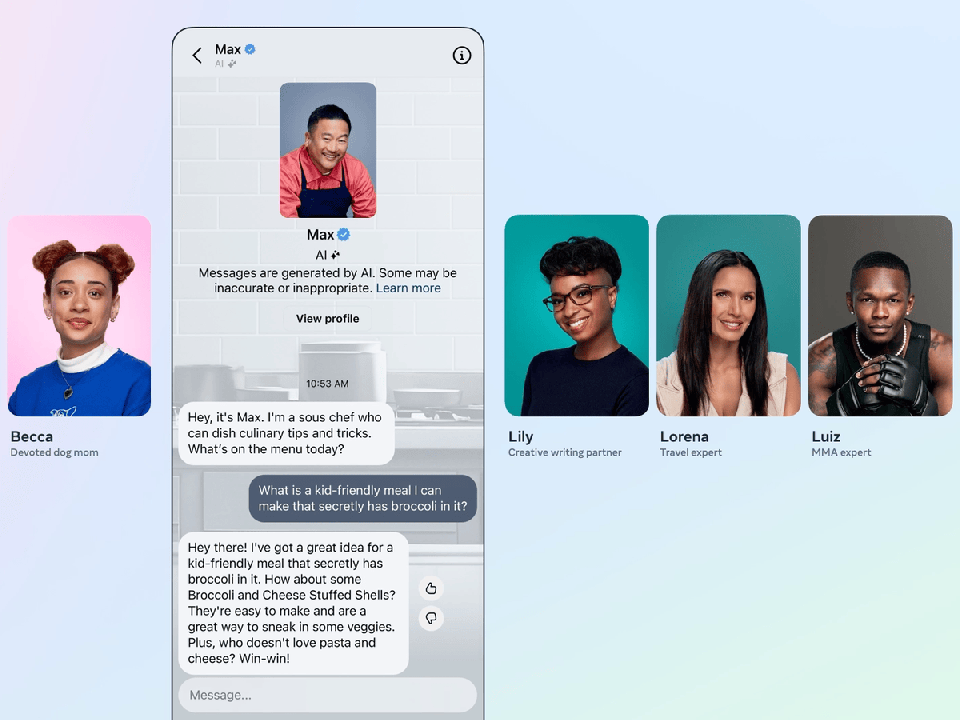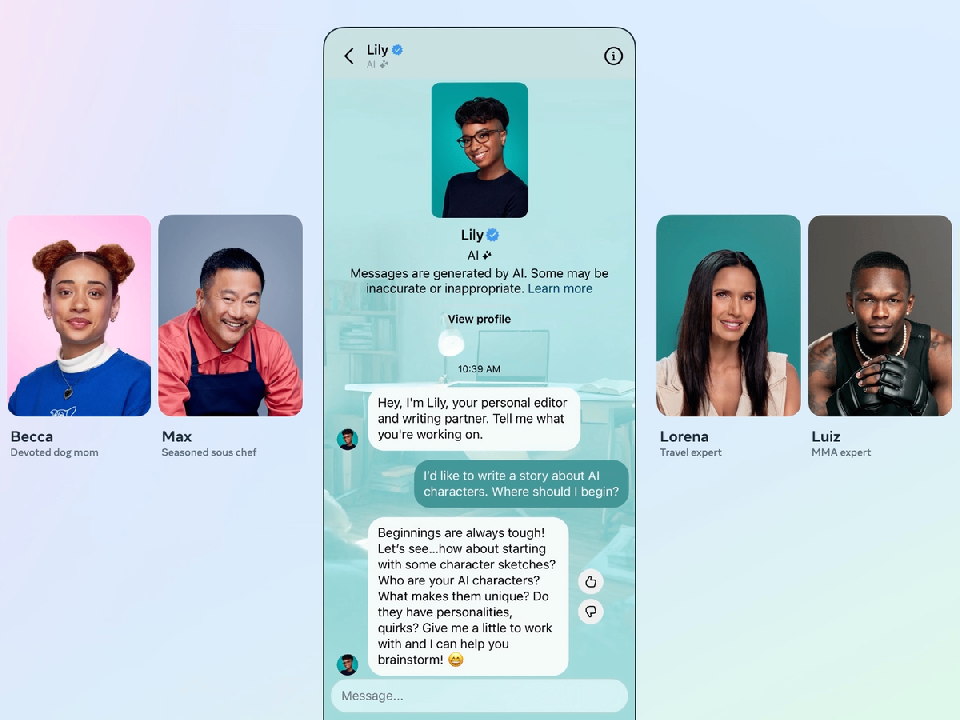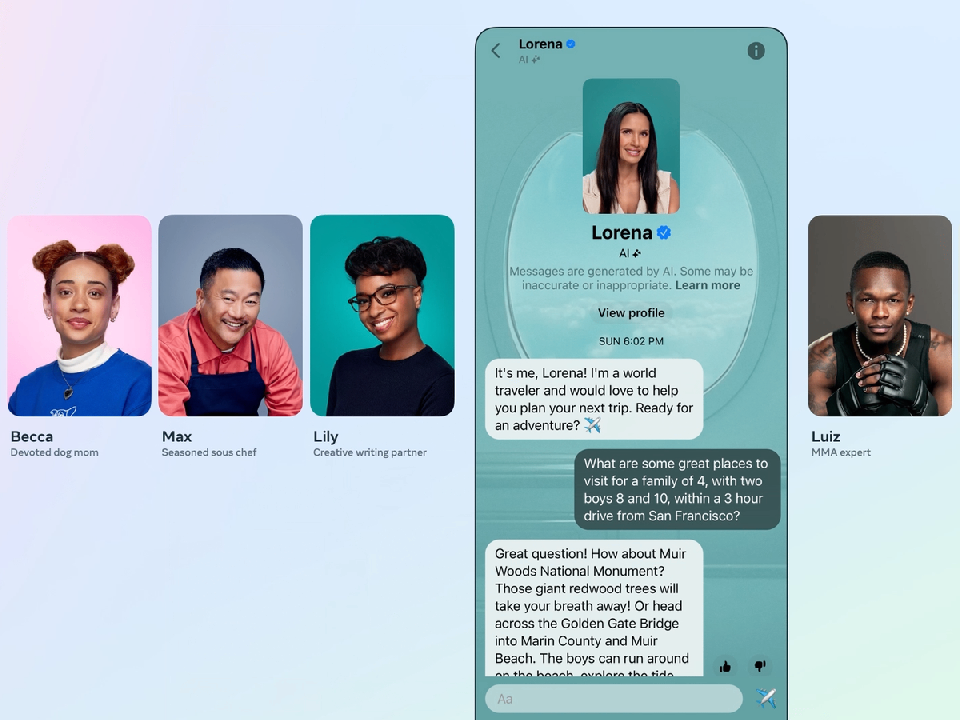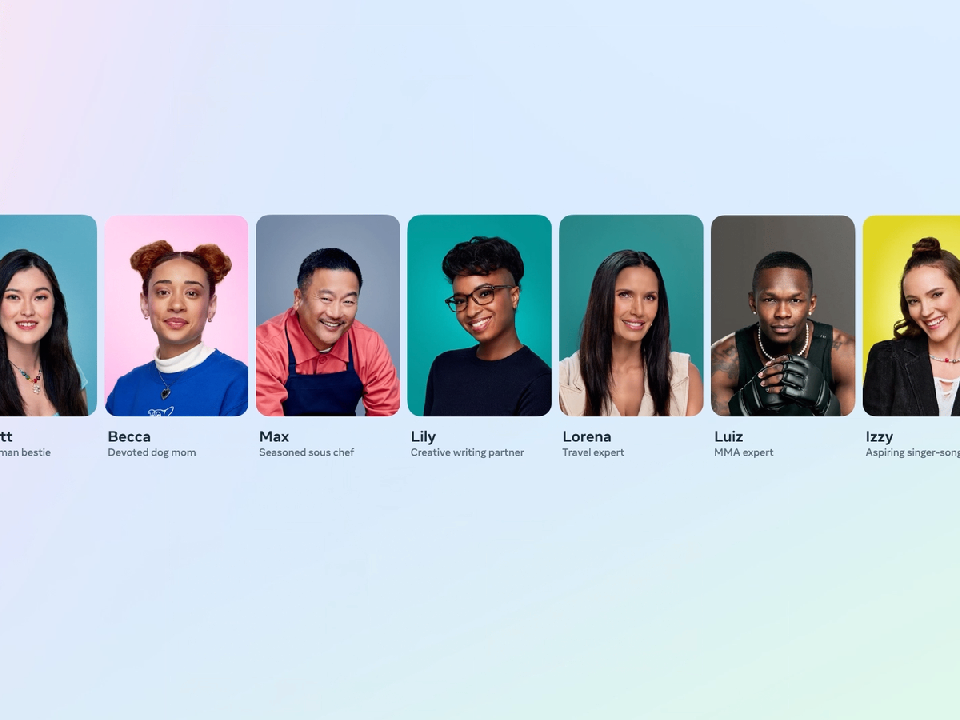
·Meta公司宣布推出Meta AI,并在旗下产品中发布了一系列个性化人工智能角色。考虑到该公司社交网络的巨大规模,其AI助手可能让大多数人第一次使用生成式人工智能。
·Meta首席执行官马克·扎克伯格强调,Meta的战略涉及为不同用途创建不同的人工智能产品,而不是单一的旗舰聊天机器人。Meta的对话机器人不仅仅是为了传达信息,其目的也是为了娱乐。
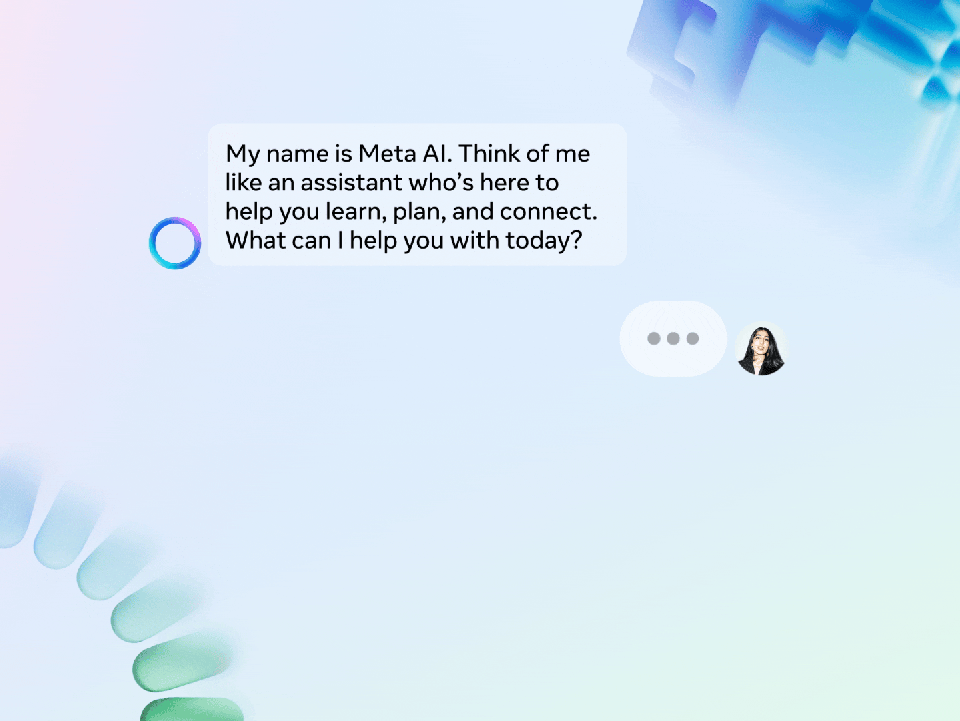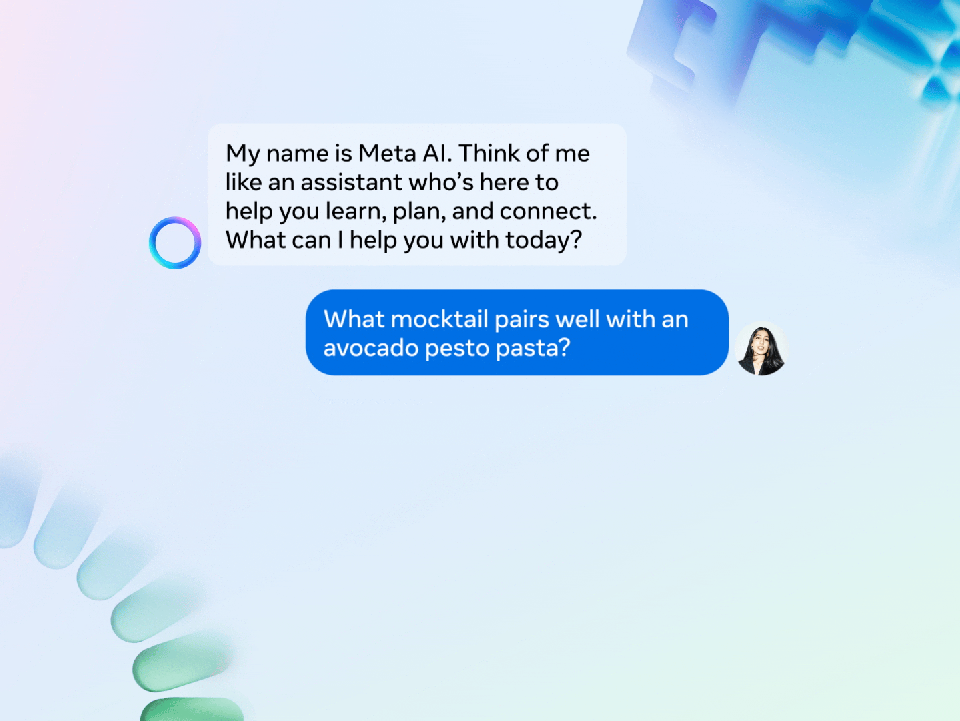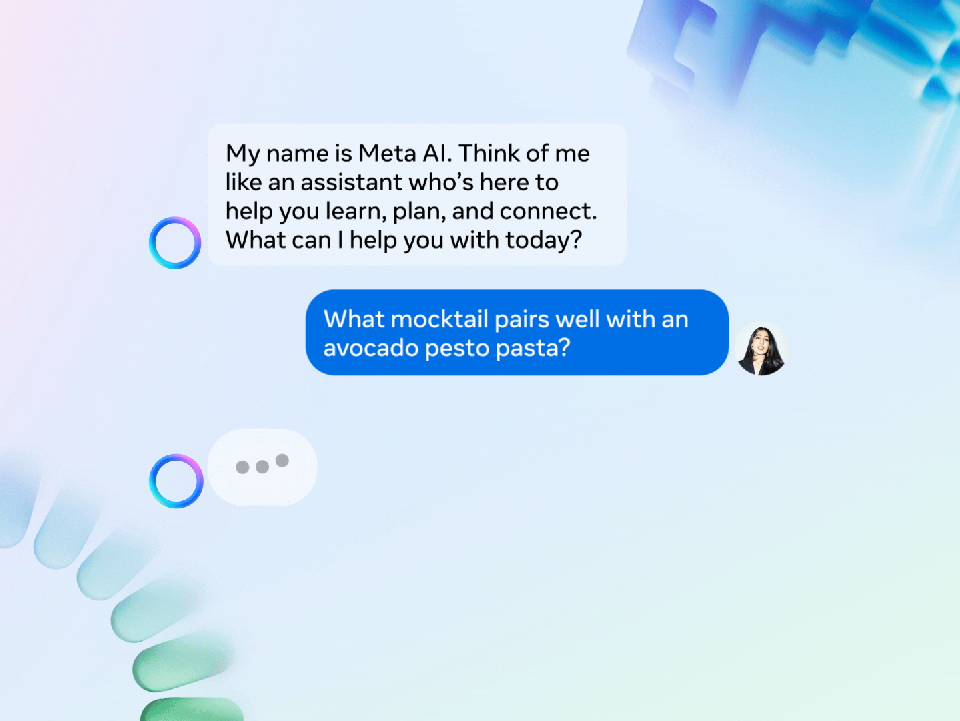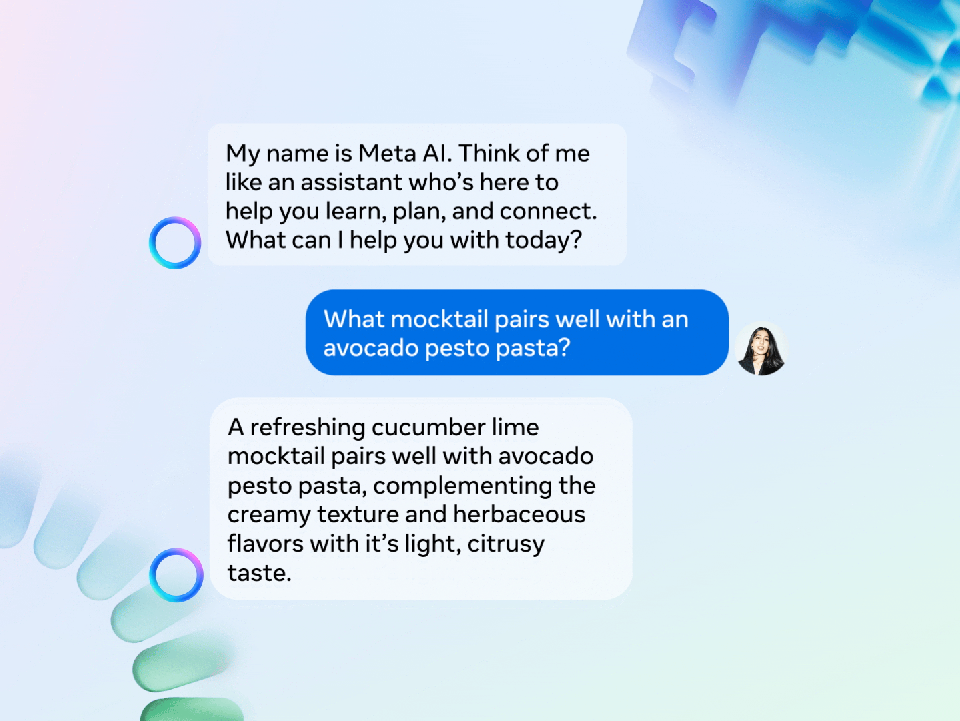
Meta AI的对话界面。
在ChatGPT诞生快一年后,Meta公司正式加入了AI聊天机器人大战。
在当地时间9月27日举行的年度Connect开发者大会上,Meta宣布推出自己的AI助手Meta AI,并在旗下产品WhatsApp、Instagram和Messenger中发布了一系列个性化人工智能角色。
尽管OpenAI和微软等公司早早开启了聊天机器人竞赛,但考虑到Meta旗下社交网络的巨大规模,其AI助手可能让大多数人第一次使用生成式人工智能。
提供实时网络结果,能够通过提示生成图像
Meta AI与其他同类聊天机器人看起来很像。Meta将其视为一个通用助手,可以处理一切事情,比如在群聊中与朋友计划旅行,回答用户通常会向搜索引擎询问的问题。Meta宣布与微软的搜索引擎Bing合作,提供实时网络结果,这使其与许多其他没有最新信息的聊天机器人区分开来。
Meta AI的另一个重要功能是它能够通过提示“/imagine”生成像Midjourney或DALL·E提供的图像,且图像生成功能完全免费。
一直领导AI助手开发的Meta生成式人工智能副总裁艾哈迈德·阿尔-达勒(Ahmad Al-Dahle)表示,Meta AI“基于Llama 2背后的许多核心原则”。Llama 2是Meta最新的开源模型,正在迅速被各个行业采用。
阿尔-达勒说,Llama 2的迅速普及帮助Meta改进了自己助手的工作方式。“我们刚刚看到了对模型的巨大需求,然后我们看到模型上发生了令人难以置信的大量创新,这些创新确实帮助我们了解了它们的性能,也了解了它们的弱点,并帮助我们迭代了其中一些组件并将其直接应用到产品中。”
但Meta AI与Llama 2不同,阿尔-达勒表示,他的团队花了很多时间“提炼额外的对话数据集,以便我们能够创建一种对话式且友好的语气,让助手做出回应。许多现有的人工智能可能像机器人一样,也可能平淡无奇。”Meta扩展了模型的上下文窗口,“这样我们就可以与用户建立更深入、更强大的交互”。他表示,Meta AI也经过调整,可以给出“非常简洁”的答案。
深度整合Instagram等社交网络
除了Meta的AI助手之外,该公司还开始在旗下应用程序中推出28个人工智能角色,其中有的以史努比狗狗和帕丽斯·希尔顿等名人为原型。其他则以特定用例为主题,例如旅行社。

Meta开始在旗下应用程序中推出28个人工智能角色。
当用户与其中一位聊天时,他们的个人资料图像会根据对话巧妙地呈现动画。
角色AI对话动画。
新的生成式人工智能工具还将允许用户使用文本提示编辑图像并创建表情包。AI图像编辑功能将在Instagram上推出,包括两个新功能:重新设计样式和背景。通过重新设计,用户输入文本提示(Meta 的示例包括“水彩”或“杂志拼贴”),该工具会根据这些指示更新现有图像。

重新设计样式功能。
背景功能利用用户的文本提示将人工智能生成的新背景添加到图像中(例如“用小狗包围我”)。
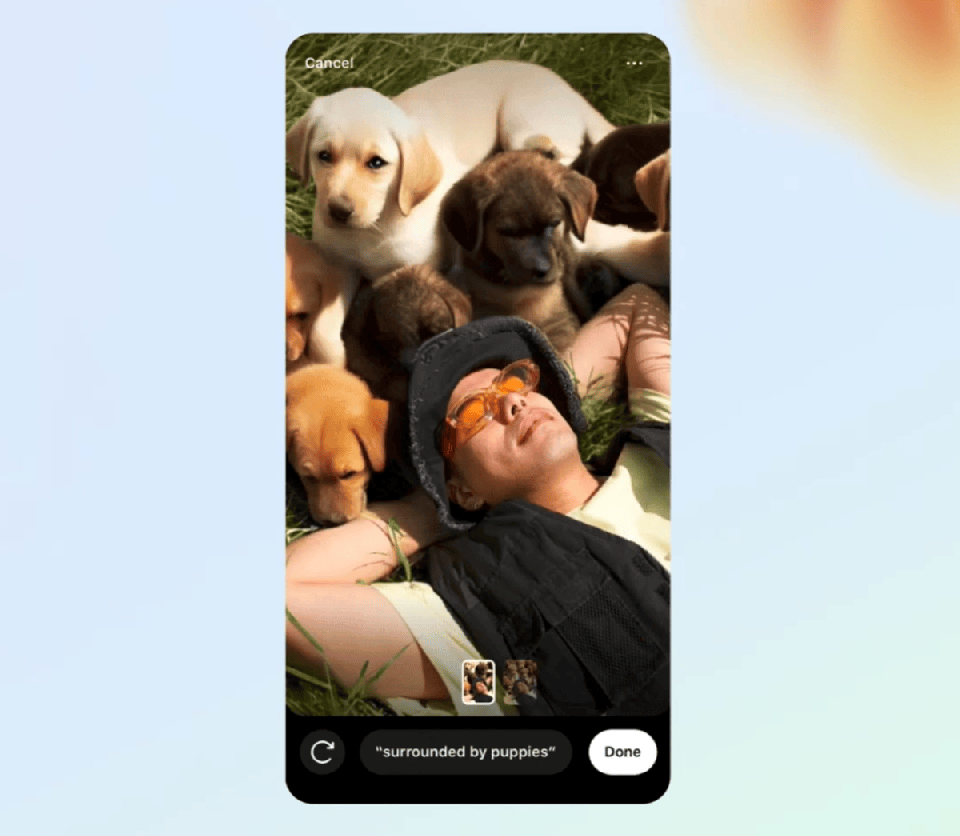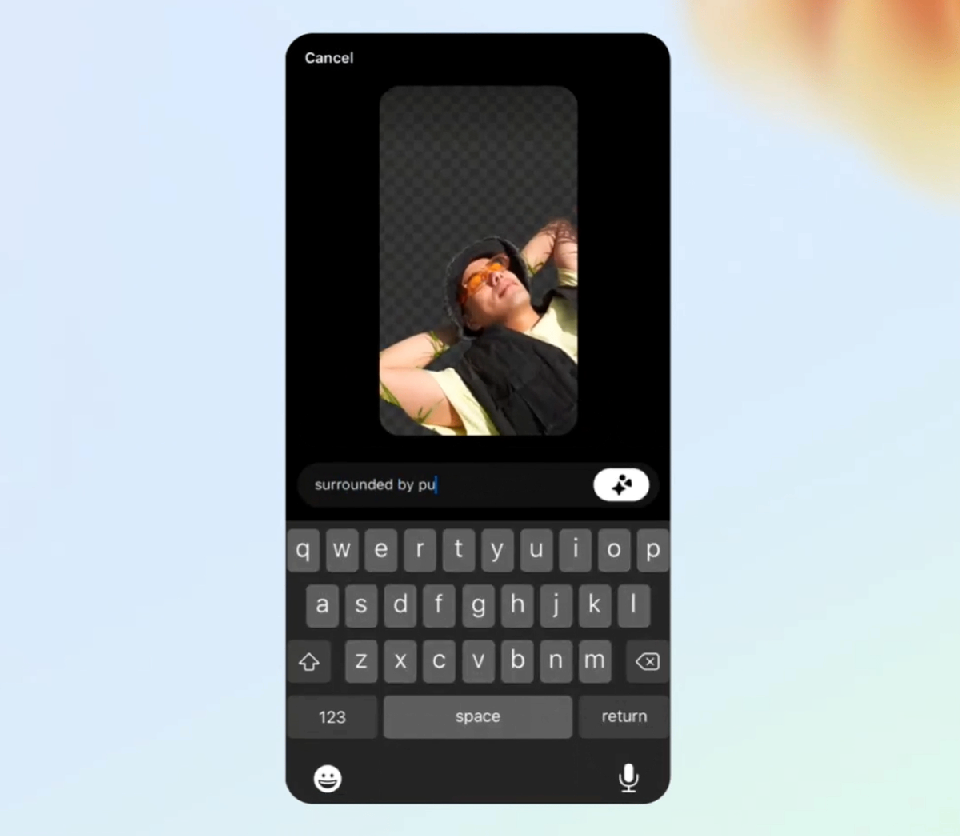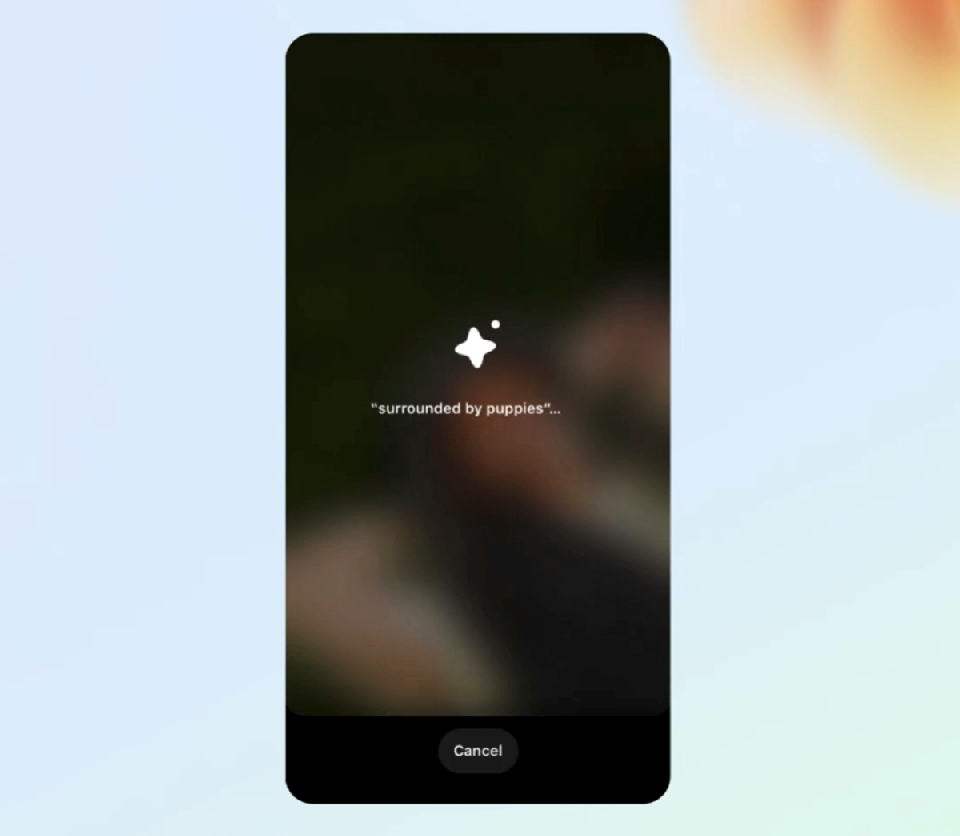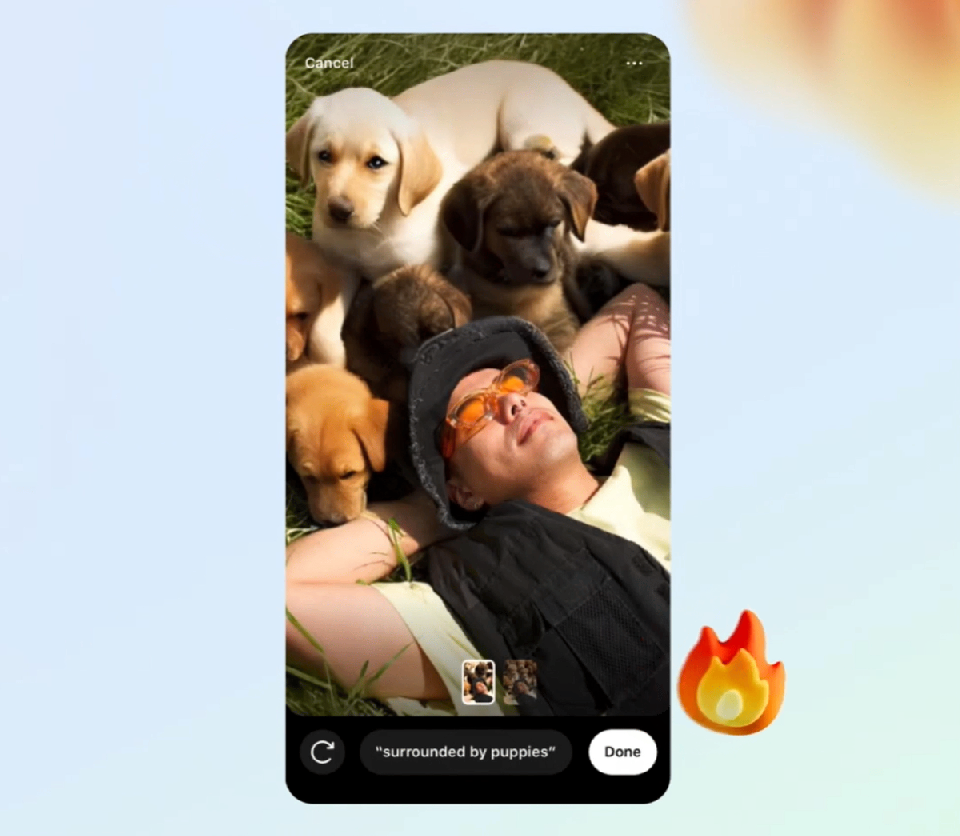
背景功能。
Meta表示,对于这两种编辑功能,它将识别何时使用人工智能工具创建图像,以便用户可以辨别所看到的内容是否是合成的。该公司表示正在尝试其他标签功能,包括可见和不可见标记。
AI生成的聊天表情包将在Instagram、Facebook、WhatsApp和Messenger上推出。用户可以选择使用文本提示创建表情包,应该会“在几秒钟内生成多个独特的高质量表情包”。这些功能都由Llama 2提供支持。

用户可以选择使用文本提示创建表情包
随着TikTok崛起,在过去几年夺走了Meta旗下Instagram的大量青少年用户,吸引年轻用户一直是Meta的首要任务。
目前,Meta AI还没有接受过Instagram和Facebook上公共用户数据的训练,未来可能会这样做,这是其他聊天机器人无法复制的特点。“我们看到了一个漫长的路线图,我们需要将我们自己的一些社交(功能)整合作为助手的一部分,以使其更加有用。”阿尔-达勒说。
9月科技公司密集更新AI功能
Meta长期以来一直是人工智能研究的强大力量,为无数功能提供支持:从在社交网络上显示病毒内容的算法到标记有毒内容的系统。但随着谷歌和OpenAI推出聊天机器人和其他独立的人工智能产品,Meta似乎在这方面落后了。
本月,科技公司都在忙着为生成式AI推出新的体验和功能。谷歌于9月19日发布了聊天机器人Bard的新版本,将其与谷歌最受欢迎的几项服务如Gmail、Docs整合。20日,亚马逊透露将“很快”让语音助手Alexa进行“近乎人类”的对话。当天,OpenAI发布了将图像生成器DALL·E 3整合到聊天机器人ChatGPT中的消息。21日,微软宣布计划将其生成式人工智能助手“Copilot”嵌入其许多产品中。25日,OpenAI宣布推出ChatGPT的新版本,用户可以通过语音或图片提示进行交互。
Meta首席执行官马克·扎克伯格强调,Meta的战略涉及为不同用途创建不同的人工智能产品,而不是单一的旗舰聊天机器人。他补充说,Meta的对话机器人不仅仅是为了传达信息,其目的也是为了娱乐。“我认为这将改变人们使用我们所有产品的方式。”扎克伯格说。
不过,Meta并不是第一个推出娱乐型聊天机器人的公司。今年早些时候,社交应用Snapchat推出了聊天机器人My AI,旨在为用户提供从汽车到筹划婚礼等方方面面的建议。去年,两名前谷歌员工推出了Character AI,允许用户模仿夏洛克·福尔摩斯或阿尔伯特·爱因斯坦对话。
前Snap和Instagram高管梅格纳·达尔(Meghana Dhar)表示:“AI聊天机器人对我来说并不完全符合‘Z世代’(Gneration Z,通常指1995年至2009年出生的一代人)的特点,但无疑‘Z世代’对这项技术更加熟悉。年龄越小,他们与这些机器人的亲近感越高。”达尔表示,如果这些AI聊天机器人能够增加用户在Facebook、Instagram和WhatsApp上的使用时间,那么它们可能会对Meta有益,“他们只是希望让用户在平台上停留更长时间,因为这给了他们更多机会来向用户提供广告服务。”
不过,研究人员发现,赋予这些聊天机器人个性可能会带来一些挑战。根据普林斯顿大学、艾伦人工智能研究所和佐治亚理工学院的研究人员今年春季发表的一篇论文,在ChatGPT中添加个性会使其输出更具毒性。
美国马萨诸塞州民主党参议员爱德华·马基(Edward J. Markey)9月27日致信扎克伯格,敦促他暂停发布人工智能聊天机器人的计划,直到该公司了解它们将对年轻用户产生的影响。Meta表示,所有人工智能模型都有能力传播不准确或不适当的内容,但该公司将继续提高其聊天机器人的安全性和准确性。
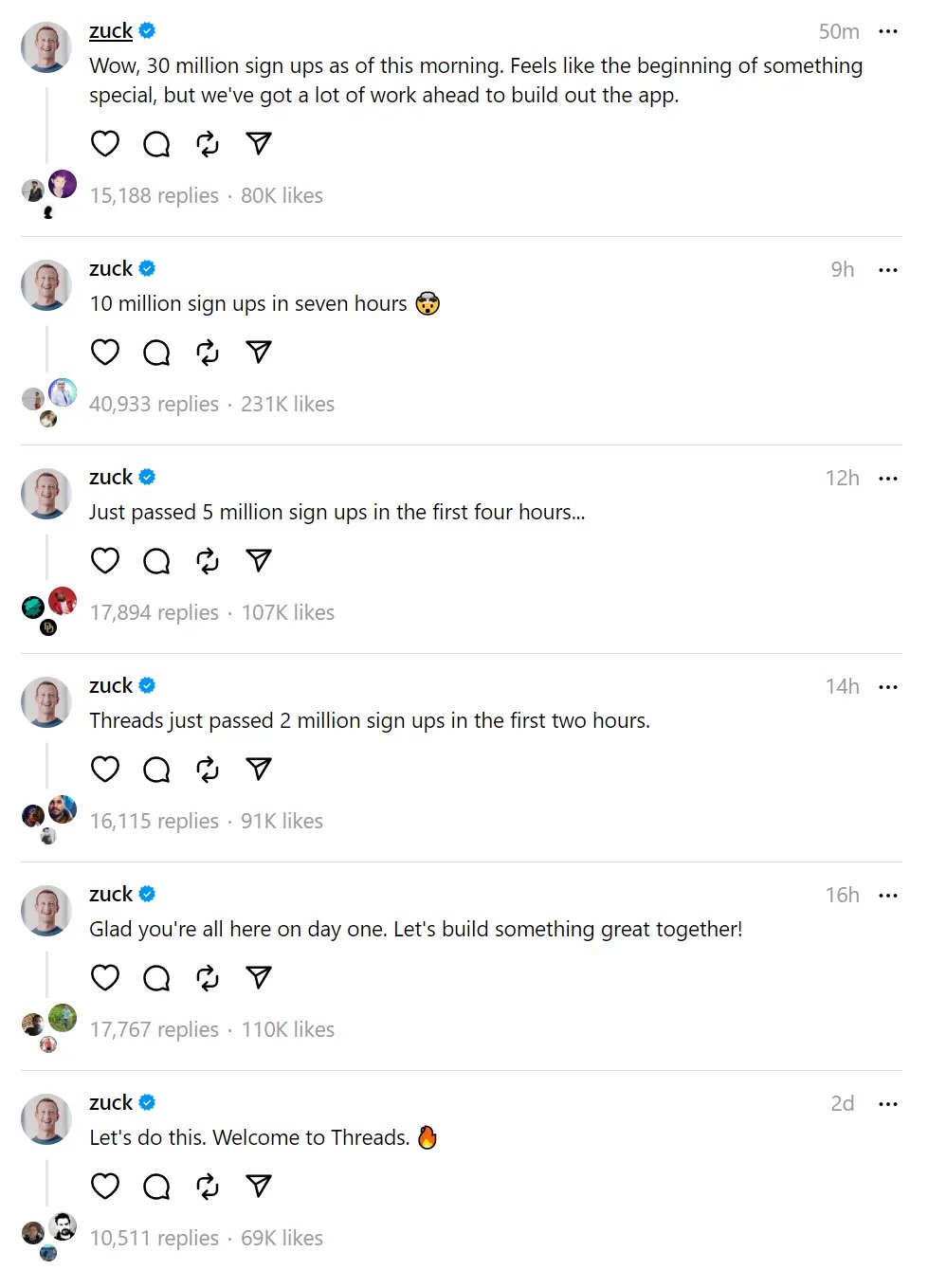
Meta首席执行官扎克伯格在网上不断更新Threads用户数。

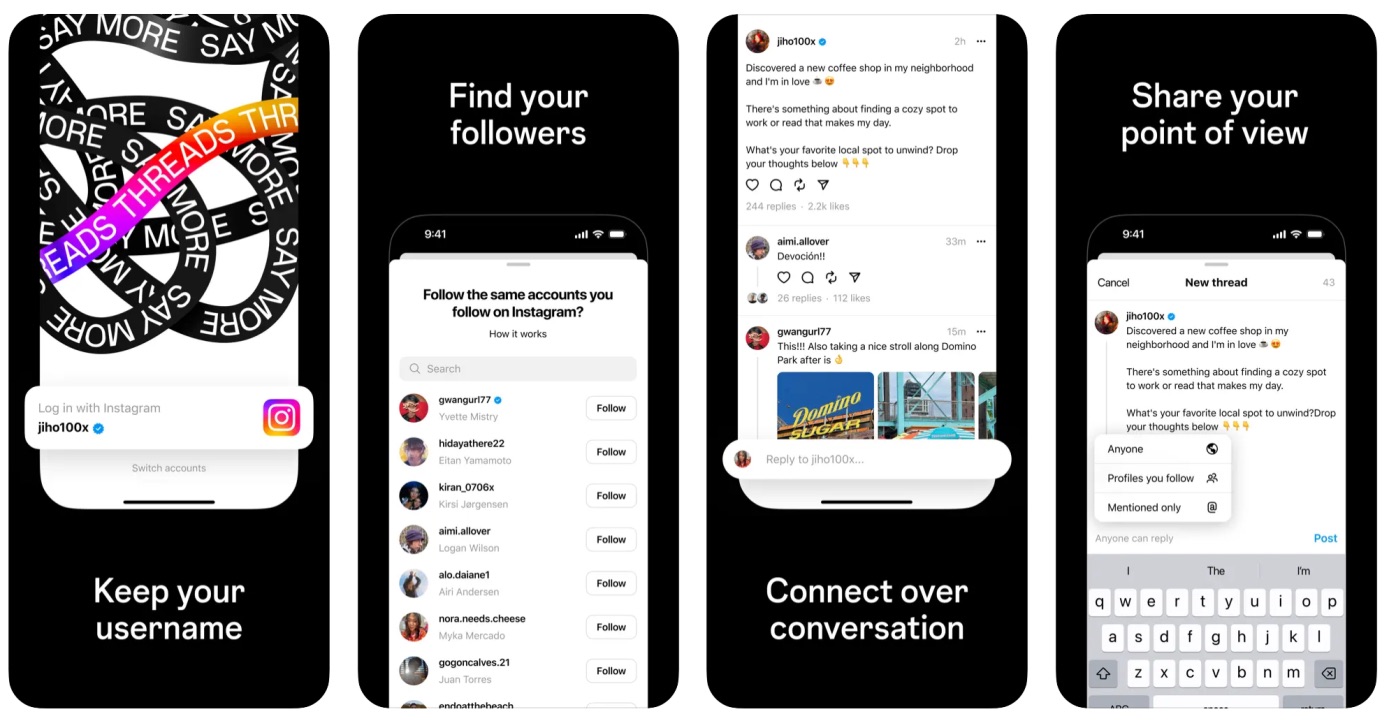
用户可以通过现有的Instagram账户轻松注册Threads,并从Instagram转移关注者。
·推特的竞争对手Threads在不到24小时内就达到了3000万注册量,而ChatGPT花费60天才拥有3000万用户,过去十年中几乎任何应用程序都无法与Threads的这个增长速度相比。
·马斯克在网上批评Threads,推特的法律团队威胁要对Threads采取法律行动,在一封信中指控Meta参与“非法盗用”其商业机密。
用户可以通过现有的Instagram账户轻松注册Threads,并从Instagram转移关注者。
在7月6日向公众推出后的第二天,Meta公司基于文本的社交应用程序Threads就迎来了用户的爆炸式增长。
根据Meta首席执行官马克·扎克伯格公布的数据,Threads在发布不到24小时内就达到了3000万注册量,而ChatGPT花费60天才拥有3000万用户,过去十年中几乎任何应用程序都无法与Threads的这个增长速度相比。而就在几天前,美国媒体还在讨论社交媒体已陷入困境的话题。
这款被评价为“看起来和推特一样”的应用程序,正是扎克伯格针对推特发起的一场“突袭”。当地时间7月6日,推特所有者埃隆·马斯克在网上批评Threads,推特的法律团队威胁要对Threads采取法律行动,在一封信中指控Meta参与“非法盗用”其商业机密。
是谁在加入Threads?
猛烈的增长势头还在继续。扎克伯格透露,截至当地时间7月7日上午,Threads的注册人数已超过7000万,这一数字“远远超出了我们的预期”。根据公司内部数据,用户已经发布了超过9500万条帖子和1.9亿个赞。
Meta首席执行官扎克伯格在网上不断更新Threads用户数。
根据统计机构Sensor Tower和data.ai向《时代》杂志提供的数据,Threads是过去十年发布日下载次数最多的非游戏应用程序。Sensor Tower称,7月6日Threads在全球的下载量已达到约4000万次。data.ai表示,任天堂的《马里奥赛车之旅》是有史以来增长最快的应用程序,Threads排名第二,其用户增长速度超过了Pokemon GO和《使命召唤手游》等流行应用程序。
根据data.ai的数据,Instagram用了15个月时间才达到3000万次下载,而TikTok用了不到两年时间达到这一里程碑。
根据《纽约时报》此前的报道,两位知情人透露,ChatGPT在发布两个月后用户数超过3000万,使其成为记忆中有史以来增长最快的软件产品之一。不过,今年5月ChatGPT的App发布后,下载量略低于1800万次。
Threads的主要吸引力在于,它与社交应用Instagram绑定在一起,用户可以通过现有的Instagram账户轻松注册,并从Instagram转移关注者。Insider Intelligence首席分析师杰斯明·恩伯格(Jasmine Enberg)在一份声明中表示:“Meta只需要四分之一的Instagram用户每月使用Threads,它的规模就能与推特一样大。”
此外,大量名人账户获得了Threads的早期访问权限,包括微软公司创始人比尔·盖茨、歌手夏奇拉和主持人奥普拉·温弗瑞等公众人物,以及Netflix等品牌。据Axios报道,截至当地时间7月6日晚间,美国国会参众两院535名议员中超过四分之一的人,以及6名共和党总统候选人和白宫高级助手都创建了Threads账户。
Meta这次能成功吗?
Meta公司已经拥有雄厚的社交媒体基础设施,旗下包括Facebook和Instagram,这些家喻户晓的名字使其处于领先地位。 “与大品牌联系在一起是一个优势。”布鲁金斯学会技术创新中心高级研究员达雷尔·韦斯特(Darrell West)告诉《时代》杂志,“Threads不会成为一个小众市场参与者。”
此外,Threads已经产生了怀旧的效果,一些用户将该应用程序的体验与早期的推特进行了比较。
美国消费者新闻与商业频道 (CNBC)评论称,虽然推特因被记者、政治家和学者广泛使用而闻名,并且是一个经常发布新闻的地方,但Threads可能会因为与Instagram的绑定而拥有更广泛的受众和关注点。此外,Meta已采取措施不再强调Facebook上的政治内容,这一政策如果延续到Threads上,可以使其与推特区分开来。
“人们不会像在推特上那样使用Threads来了解新闻和全球事件,而且文化也会有所不同。但这可能对Meta有利:即使是最活跃的推特用户也厌倦了持续的混乱和临时变化,而Threads可以提供一个很好的缓解。”恩伯格写道。
科技博客The Split认为,Threads所做的最聪明的事,是采用了类似TikTok一样的瀑布流,用户看到的不止是关注者的内容,还包括平台上的其他推荐内容。
不过,单靠增长迅猛还不足以让Threads成为推特的替代品,经受住时间的考验。它必须证明有能力保持用户的参与度和回头率。
弗吉尼亚大学媒体研究系助理教授凯文·德里斯科尔(Kevin Driscoll)表示,Threads的成功能否持续还有待观察。 “推特和脸书都出现了一些问题,并且是这些高度中心化平台所特有的问题,它们的主要关注点是增长、规模以及早期用户获取,因此没有太多谈论长期可持续性。”
Threads仍然缺乏一些关键功能,例如搜索、主题标签和关注流。Meta也因一项政策受阻,该政策要求用户在尝试删除其Threads账户的同时也删除其Instagram的个人资料。Meta的首席技术官安德鲁·博斯沃思(Andrew Bosworth)在Threads帖子中表示,该公司正在努力修复这个问题。
由于监管方面的担忧,Meta在欧盟国家推出Threads还面临挑战。该地区是Meta的一个重要市场。据《华尔街日报》报道,2023年第一季度该公司280亿美元的广告收入中,欧洲约占22%。
推特的反击和小扎的翻身
扎克伯格并不回避对推特进行猛烈抨击,他在一篇帖子中表示,Threads将“专注于善意”,暗示推特缺少这一点。 “这就是推特从未取得我认为应有的成功的原因之一,我们希望采取不同的做法。”他说。
Threads也被许多人称为“推特杀手”,对马斯克今年早些时候建立的X公司构成威胁。据新兴媒体Semafor报道,就在Threads推出几小时后,X公司的法律团队致函扎克伯格,表达了“对Meta系统性、故意性和非法盗用推特商业机密和其他知识产权的严重担忧”。Meta发言人对此回应称:“Threads工程团队中没有人是推特前员工——这根本不是一回事。”
马斯克在一系列推文中批评了Threads,称其为“闭源、只有算法的系统”,暗示这可能意味着“对人们所看到的信息的操纵基本上是无法检测到的”。在回复有关Meta在社交媒体占主导地位的推文时,他写道:“任何社交媒体垄断都是令人绝望的。”
值得注意的是,Instagram负责人亚当·莫斯利(Adam Mosseri)表示,Threads发布时不会提供ActivityPub支持。ActivityPub是一种用于在去中心化网络上发布信息的协议。但Threads计划在未来允许与其他Fediverse(联邦宇宙)服务器进行交互。
联邦宇宙由一系列用户自建或第三方托管的互相连接的服务器组成,虽然各个服务器是独立运行的,但在这些服务器上所运行的软件支持一种或多种遵循开放标准的通信协议,这样不同服务器的数据就可以互联互通。也就是说,如果推特和Facebook都加入联邦宇宙,那么用户就可以用推特账户去关注Facebook的好友,还能跟他互动、聊天、发文件。
Threads的出场有望让扎克伯格打一场翻身仗。Meta近年来的发展并不顺利,发生了一系列备受瞩目的丑闻和失误,包括大规模裁员,活动人士和监管机构批评该公司未能保护用户免受平台伤害以及对用户数据处理不当。2021年该公司高调推出的元宇宙战略也进展缓慢。
“这是我们所希望的一个良好的开始!”扎克伯格在Threads上发帖,“感觉像是一些特别的事情的开始。”